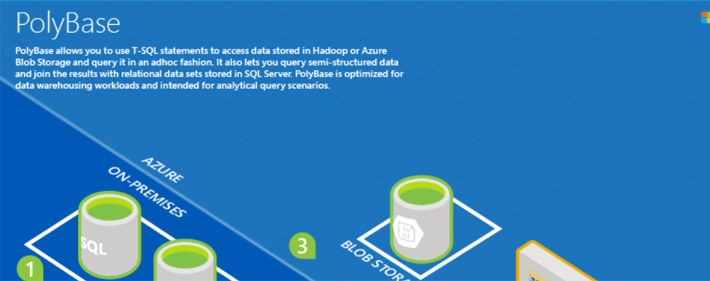
Une des grandes nouveautés de SQL Server 2016 est la mise à disposition de Polybase, un nouveau service qui va nous permettre d’utiliser des données disponibles dans SQL Server mais aussi dans votre / vos clusters Hadoop, dans un stockage Azure (pour récupérer les données d’HDInsight par exemple).
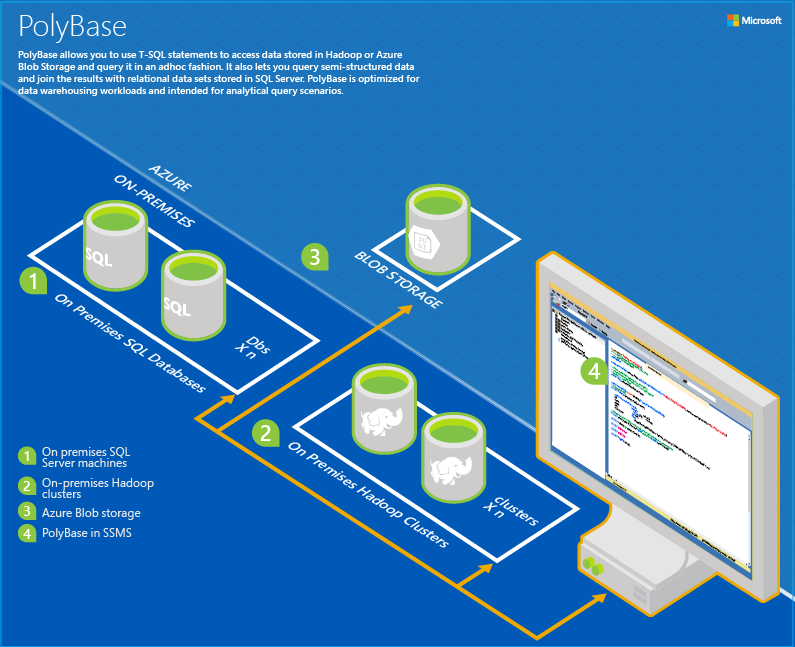
Extrait de la documentation de Polybase sur SQL Server 2016
1- Les pré-requis à l’utilisation de Polybase :
Premièrement, il est nécessaire d’installer le service lors de l’installation de SQL Server 2016
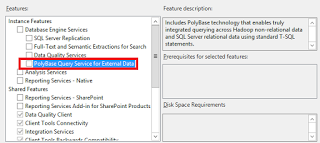
Ceci implique d’avoir installé au préalable Java RunTime Environment (Oracle JRE) sur votre serveur (Je sais, vous n’avez pas envie… mais c’est comme ça)
2- Ajouter une table externe basée sur un container Azure
Voici les étapes à réaliser afin d’ajouter une table externe qui permet d’accéder de façon transparente aux données stockées dans un container Azure.
A. Configurer Polybase afin d’accéder aux données Azure :
sp_configure 'hadoop connectivity', 7; reconfigure
Ici nous choisissons 7 afin de pouvoir accéder à Azure mais aussi aux cluster Hortonworks.
- Option 0: Disable Hadoop connectivity
- Option 1: Hortonworks HDP 1.3 on Windows Server
- Option 1: Azure blob storage (WASB[S])
- Option 2: Hortonworks HDP 1.3 on Linux
- Option 3: Cloudera CDH 4.3 on Linux
- Option 4: Hortonworks HDP 2.0 on Windows Server
- Option 4: Azure blob storage (WASB[S])
- Option 5: Hortonworks HDP 2.0 on Linux
- Option 6: Cloudera 5.1 on Linux
- Option 7: Hortonworks 2.1 and 2.2 on Linux
- Option 7: Hortonworks 2.2 on Windows Server
- Option 7: Azure blob storage (WASB[S])
Plus d’informations ici => https://msdn.microsoft.com/en-us/library/mt143174.aspx
B. Créer nos informations d’identification
La méthode ci-dessous est temporaire, une version plus « Industrialisée » devrait être disponible à la sortie en RTM de SQL Server 2016.
Nous allons donc créer une Master Key sur la base de données de notre exemple (SecuriteSociale) puis créer un « Credential » de base de données (Attention, pour ce faire il faut activer le traceflag 4631 car cette fonctionnalité n’est pas encore disponible)
DBCC TRACEON(4631,-1) USE SecuriteSociale CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'scopit'; CREATE CREDENTIAL WASBCredential ON DATABASE WITH IDENTITY = 'polyscopit', Secret = '2ZWJHiAOhT4Y9YdVehhg8JHI3FER4tRnvJtXdDeweB/MAZGRKGd9C1dL6hudA/ttltskyC3gtkvjlb07GzIw==';
C. Créer notre source de données externe
Il nous est maintenant possible de créer notre source de données externe via le script suivant :
CREATE EXTERNAL DATA SOURCE Azure_Storage with ( TYPE = HADOOP, LOCATION ='wasb://secu@polyscopit.blob.core.windows.net/', CREDENTIAL = WASBCredential )
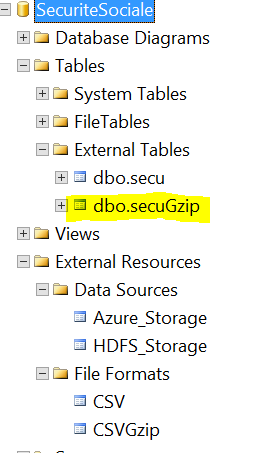
Une fois le script exécuté nous retrouvons notre source de données dans SSMS:
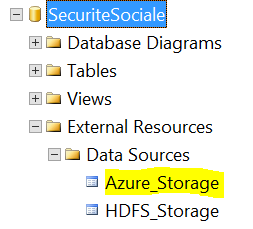
Attention, aucun test de connexion n’est réalisé (et c’est bien dommage) en cas d’erreur lors des différentes étapes, vous ne saurez ce qui cloche que lors de la création de la table.
D. Création du format de fichier
Afin de pouvoir rendre le contenu de notre fichier sous forme de table, il va être nécessaire de spécifier à Polybase la structure de celui-ci et donc de créer un File Format.
Exemple avec notre fichier en CSV avec un séparateur « ; » :
CREATE EXTERNAL FILE FORMAT CSV WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ';' ) );
Mais nous aurions aussi pu garder le fichier GZipé et appliquer le File Format suivant (c’est d’ailleurs recommandé):
CREATE EXTERNAL FILE FORMAT CSVGzip WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS ( FIELD_TERMINATOR = ';' ), DATA_COMPRESSION = 'org.apache.hadoop.io.compress.GzipCodec' );
Polybase sait maintenant où trouver les données, avec quelles informations il doit s’authentifier, et la structure des données, il ne nous reste plus qu’à créer notre table externe.
E. Créer une table externe
C’est maintenant le moment d’indiquer le nom de nos colonnes, ainsi que leur type de données.
CREATE EXTERNAL TABLE [dbo].[secuGzip] ( FLX_ANN_MOI varchar(255), ORG_CLE_ZEAT varchar(255), AGE_BEN_SNDS varchar(255), BEN_RES_ZEAT varchar(255), BEN_CMU_TOP varchar(255), BEN_QLT_COD varchar(255), BEN_SEX_COD varchar(255), DDP_SPE_COD varchar(255), ETE_CAT_SNDS varchar(255), ETE_ZEAT_COD varchar(255), ETE_TYP_SNDS varchar(255), ETP_ZEAT_COD varchar(255), ETP_CAT_SNDS varchar(255), MDT_TYP_COD varchar(255), MFT_COD varchar(255), PRS_FJH_TYP varchar(255), PRS_ACT_COG varchar(255), PRS_ACT_NBR varchar(255), PRS_ACT_QTE varchar(255), PRS_DEP_MNT varchar(255), PRS_PAI_MNT varchar(255), PRS_REM_BSE varchar(255), PRS_REM_MNT varchar(255), FLT_ACT_COG varchar(255), FLT_ACT_NBR varchar(255), FLT_ACT_QTE varchar(255), FLT_PAI_MNT varchar(255), FLT_DEP_MNT varchar(255), FLT_REM_MNT varchar(255), SOI_ANN varchar(255), SOI_MOI varchar(255), ASU_NAT varchar(255), ATT_NAT varchar(255), CPL_COD varchar(255), CPT_ENV_TYP varchar(255), DRG_AFF_NAT varchar(255), ETE_IND_TAA varchar(255), EXO_MTF varchar(255), MTM_NAT varchar(255), PRS_NAT varchar(255), PRS_PPU_SEC varchar(255), PRS_REM_TAU varchar(255), PRS_REM_TYP varchar(255), PRS_PDS_QCP varchar(255), EXE_INS_ZEAT varchar(255), PSE_ACT_SNDS varchar(255), PSE_ACT_CAT varchar(255), PSE_SPE_SNDS varchar(255), PSE_STJ_SNDS varchar(255), PRE_INS_ZEAT varchar(255), PSP_ACT_SNDS varchar(255), PSP_ACT_CAT varchar(255), PSP_SPE_SNDS varchar(255), PSP_STJ_SNDS varchar(255), TOP_PS5_TRG varchar(255), ) WITH (LOCATION='P201412.csv.gz', DATA_SOURCE = Azure_Storage, FILE_FORMAT = CSVGzip)
Et voilà, notre table (qui pointe vers un fichier stocké dans Azure) est maintenant disponible depuis SQL Server comme n’importe quelle table.
Il m’est donc possible de l’interroger directement depuis SSMS et le plus beau dans tout cela, c’est que Polybase est capable de pousser des opérations coté HDFS / Azure afin de pré-filter les données et donc limiter la charge côté serveur On-Prem.
SELECT count(*) FROM [dbo].[secuGZip]
Conclusion :
Je suis assez confiant en l’avenir de Polybase, pouvoir interroger des données extrêmement volumineuses et variées et cela simplement, c’est une promesse qui me plait beaucoup. J’imagine déjà un nombre important de scénarios où il serait intéressant de croiser des données présentes dans Hadoop à des données présentes dans notre DW relationnel. En résumé, si les performances sont au rendez-vous (des problèmes existent actuellement sur le TOP …) et que la solution s’industrialise un peu (Configuration des credentials …) nous risquons de voir polybase sur de nombreux projets.


6 Comments
Belle entrée en matière, par contre j’ai du mal à partager ton enthousiasme de la conclusion.
J’étais pourtant assez impatient d’avoir polybase à disposition parce qu’avant uniquement réservé à APS/PDW. Mais maintenant qu’il est dispo, j’ai du mal à associer les business cases. Au final si on veut s’affranchir de rapatrier les grosses volumétries côté SQL Server, pourquoi ne pas pousser les tables de faible volumétrie dont on a besoin directement sur le cluster. Cela permet en plus de ne pas être limité par la seule utilisation de polybase, mais bien de pouvoir utiliser tous les composants disponibles dans Hadoop.
De plus, je suis gêné par le développement d’un nouveau moteur from scratch. Microsoft a investi pas mal d’argent/ressource sur Hive en partenariat avec Hortonworks avec des avancées et des développements vraiment intéressants (Tez/vectorisation/CBO), c’est dommage de ne pas profiter de ces avancées sur Polybase qui corrige-moi si je me trompe n’exécute que du code MR. Quand on sait qu’en plus Hive est en constante évolution… (je pense à l’utilisation d’un moteur Spark), j’ai peur que Polybase n’accuse trop de retard en terme de performance.
A la rigueur, je pouvais comprendre l’existence de Polybase dans l’appliance APS (Serveur SQL Server et Cluster Hadoop sur la même machine). Cela permettait d’avoir un point d’entrée unique pour interroger ses données.
Mais au final, dans SQL server 2016, l’avantage que je vois maintenant, c’est l’écriture des requêtes permettant d’attaquer du Hadoop dans Management Studio, ce qui semble plutôt léger.
Tout ça pour dire qu’en fait je préférerais peut-être un support de Hive dans Management Studio (et sachant que le driver ODBC existe, ça pourrait être simple)
David
Édition de Sauget Charles-Henri :
— Plus de détails ici => http://djuber.net/2015/07/06/reflexions-autour-de-polybase-sql-server-2016/
Hello David,
Merci pour ton commentaire détaillé, je te rejoins sur ces différents points, disons que je vois dans polybase la possibilité de garder nos habitudes actuelles, les backups comme on sait les faire, la compatibilité avec nos vieux outils de reporting (SSRS, ROLAP, Autres) qui ne saurait pas encore interroger du Hive Nativement. En somme un moyen de commencer des transitions plus légères que de tout migrer dans Hadoop. Un peu comme le propose les tables en mémoire de SQL Server, avoir l’option table externe me plait 🙂 Mais encore une fois tes arguments sont excellents.
[…] ajouté un commentaire sur l’excellent article de Charles-Henri dédié à la prise en main de l’outil, c’est ce commentaire que je […]
[…] d’utiliser HDInsight, ou encore dans certains cas d’utilisation de Polybase vous allez devoir placer vos fichiers sur Windows Azure Blob Storage, or ce n’est pas […]
wow SQL 2106 have you found the wormhole? quite far ahead 😉
Ahah good catch, back to the future ! 2016 is far enough!