Récemment je me suis vu interdire d’utiliser des Azures Functions sur un projet… Et vu que j’ai du DataBricks sur celui-ci (pour charger du gros XML qui tâche…) je me suis donc naturellement dirigé vers celui-ci pour charger mes fichiers Excel ! 😀
Et oui ! Qui mieux qu’un cluster Spark peut charger un fichier Excel de 3 Mo ?
Je vous passe la configuration d’accès au Data Lake que vous retrouverez ici => https://sauget-ch.fr/2019/03/adls-gen2-databricks/
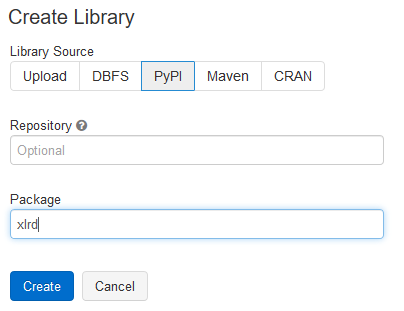
Première étape, récupérer le contenu du fichier avec pandas. Pour que cela fonctionne, il est nécessaire d’ajouter la librairie python xlrd au cluster car celle-ci n’est pas automatiquement ajoutée avec pandas.
Et c’est parti pour le script PySpark…..
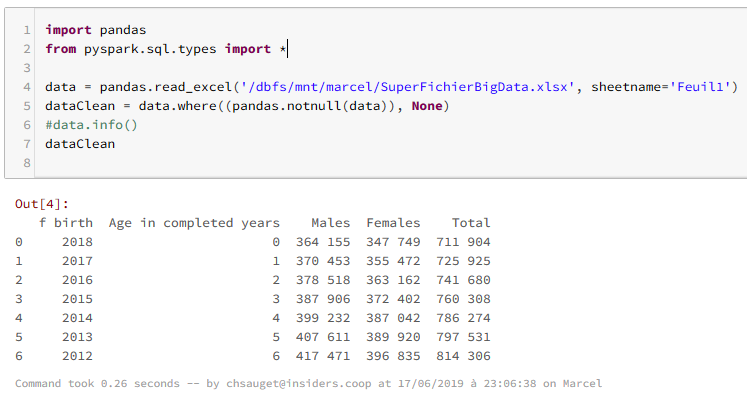
import pandas
from pyspark.sql.types import *
data = pandas.read_excel('/dbfs/mnt/marcel/SuperFichierBigData.xlsx', sheetname='Feuil1')
dataClean = data.where((pandas.notnull(data)), None)
data.info()
dataClean
Cela en n’oubliant pas de préfixer le chemin par /dbfs/
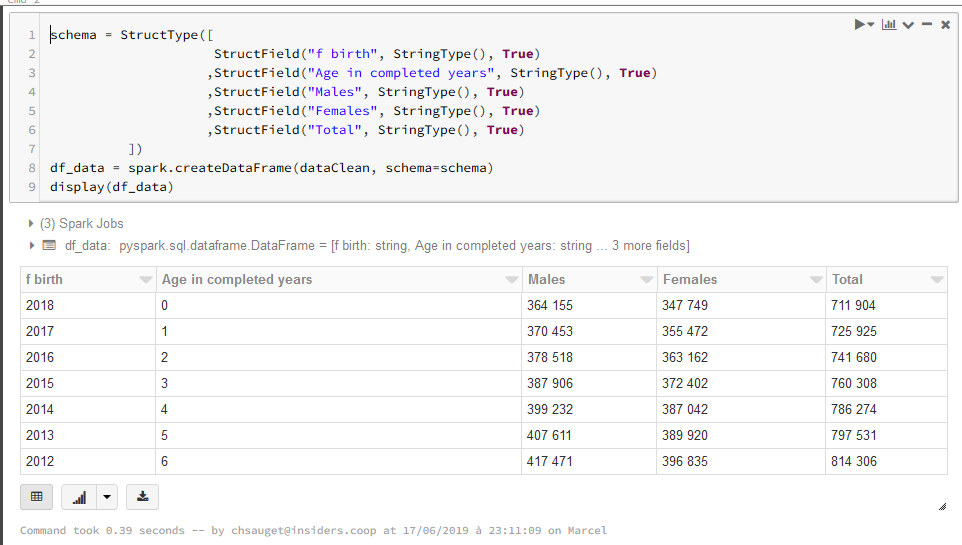
Il est ensuite nécessaire de convertir le dataframe pandas en dataframe spark. Spécifier le schéma évite les erreurs de conversion.
schema = StructType([
StructField("f birth", StringType(), True)
,StructField("Age in completed years", StringType(), True)
,StructField("Males", StringType(), True)
,StructField("Females", StringType(), True)
,StructField("Total", StringType(), True)
])
df_data = spark.createDataFrame(dataClean, schema=schema)
display(df_data)
Félicitations, vous venez d’utiliser une fusée pour tuer une mouche ! Merci l’équipe de sécu !
One comment
Ou un bulldozer pour se décrotter le nez 🙂