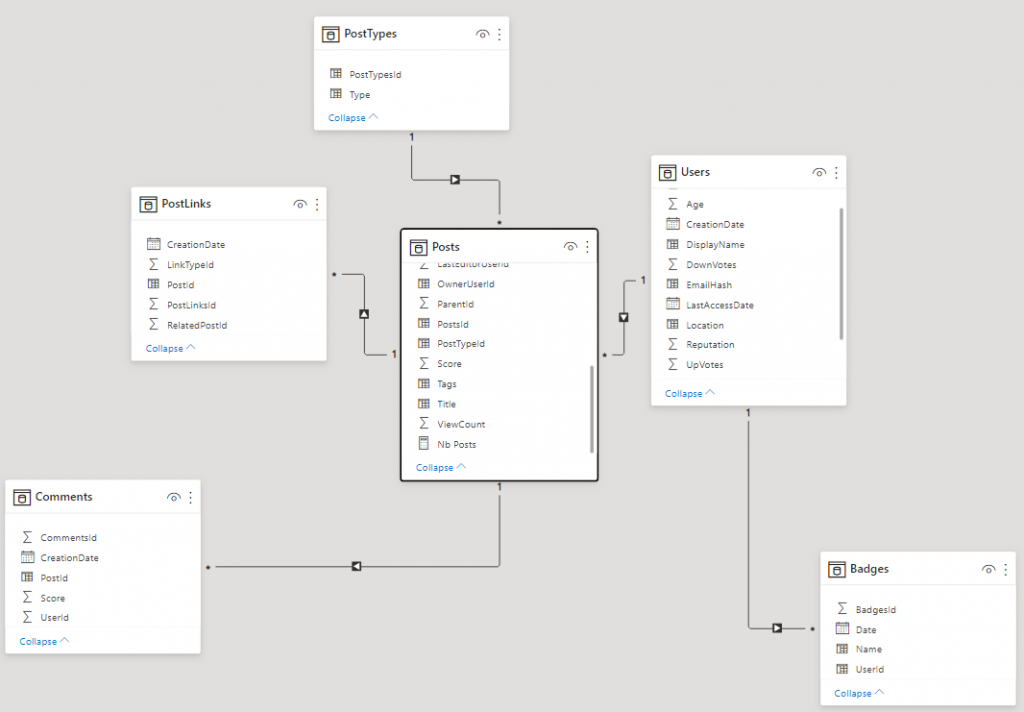
La première difficulté pour discuter d’une fonctionnalité AAS / PowerBI est de réaliser un environnement de test qui soit intéressant, c’est pourquoi je me suis tourné vers la base de StackOverflow proposée par Brent Ozar. La version Extra-Large a le mérite de faire plus de 300 GO de données et de fournir plusieurs axes d’analyse intéressent. Le modèle tabulaire utilisé pour cet exemple fait environ 10 GO.
Implémentation
Pour cet exemple, prenons un cas d’usage vieux comme les modèles Analysis Services eux-même ! https://www.sqlbi.com/articles/datetool-dimension-an-alternative-time-intelligence-implementation/ L’implémentation de deux axes d’analyses dédiés à l’agrégation et à la comparaison des données temporelles.
DateAggregation, une dimension permettant de choisir entre les valeurs suivantes :
- Regular
- Year To Date
- Last 12 Months
- Total Current Year
DateComparison, une dimension permettant de choisir la représentation de ces données :
- Regular
- Previous Year
- Diff. Over Previous Year
- Diff. % Over Previous Year
Prendre cet exemple me permet de réaliser qu’il aura fallu 8 ans avant de pouvoir enfin retrouver la capacité de faire ce type d’implémentation proprement, tout à fait classique sur SSAS Multidimensionnel (mais bon on va pas faire le vieux 👴🏼 … ).
Avant les Calculation Groups
La solution la plus simple sans Calculation Group est d’utiliser un SWITCH, un SELECTEDVALUE, et deux tables DAX de référence comme ci-dessous.
DateAggregation = DataTable("DateAggregation", STRING
,{
{"Regular"},
{"Year To Date"},
{"Last 12 Months"},
{"Total Current Year"}
}
)
DateComparison = DataTable("DateComparison", STRING
,{
{"Regular"},
{"Previous Year"},
{"Diff. Over Previous Year"},
{"Diff. % Over Previous Year"}
}
)
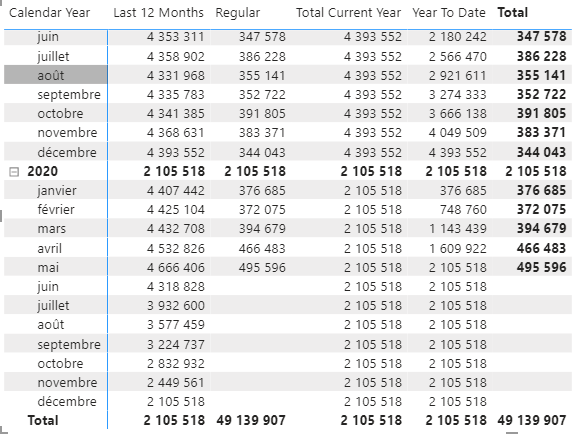
Maintenant choisissons une mesure, car en effet une des limites de cette approche est que le code va devoir s’appliquer sur chaque mesures…
J’ai donc une mesure Nb Posts qui représente le nombre de questions sur Stack Overflow.
Nb Posts = COUNTROWS('Posts')Pour la compréhension de l’exemple, séparons les différentes étapes en différentes mesures :
Nb Posts DateAggregation = SWITCH(SELECTEDVALUE('DateAggregation'[DateAggregation],"Regular")
,"Regular",[Nb Posts]
,"Year To Date",CALCULATE([Nb Posts],DATESYTD('Date'[Date]))
,"Last 12 Months",CALCULATE ( [Nb Posts],
DATESINPERIOD (
'Date'[Date],
MAX ( 'Date'[Date] ),
-1,
YEAR
)
)
,"Total Current Year",CALCULATE([Nb Posts]
,FILTER(ALL('Date')
,VALUE('Date'[Calendar Year])=YEAR(MAX('Date'[Date]) )
)
)
)
L’intégration de la mesure utilisant DateComparison permettant de comparer les dates est réalisée avec la mesure suivante.
Nb Posts DateComparison =
SWITCH (
SELECTEDVALUE ( 'DateComparison'[DateComparison], "Regular" ),
"Regular", [Nb Posts DateAggregation],
"Previous Year",
CALCULATE (
[Nb Posts DateAggregation],
PARALLELPERIOD ( 'Date'[Date], -1, YEAR )
),
"Diff. Over Previous Year",
CALCULATE (
[Nb Posts DateAggregation],
PARALLELPERIOD ( 'Date'[Date], -1, YEAR )
) - [Nb Posts DateAggregation],
"Diff. % Over Previous Y",
DIVIDE (
[Nb Posts DateAggregation]
- CALCULATE (
[Nb Posts DateAggregation],
PARALLELPERIOD ( 'Date'[Date], -1, YEAR )
),
CALCULATE (
[Nb Posts DateAggregation],
PARALLELPERIOD ( 'Date'[Date], -1, YEAR )
)
)
)On remarque qu’il est donc nécessaire d’imbriquer les deux mesures ce qui crée de facto un lien fort entre les deux types d’analyses DateAggregation et DateComparison. Cela est obligatoire si l’on veut pouvoir mixer ces axes (et si je voulais croiser 3, 4, 5 axes je serais de la même façon obligé de continuer cette encapsulation ou de démultiplier mes sorties de switch).
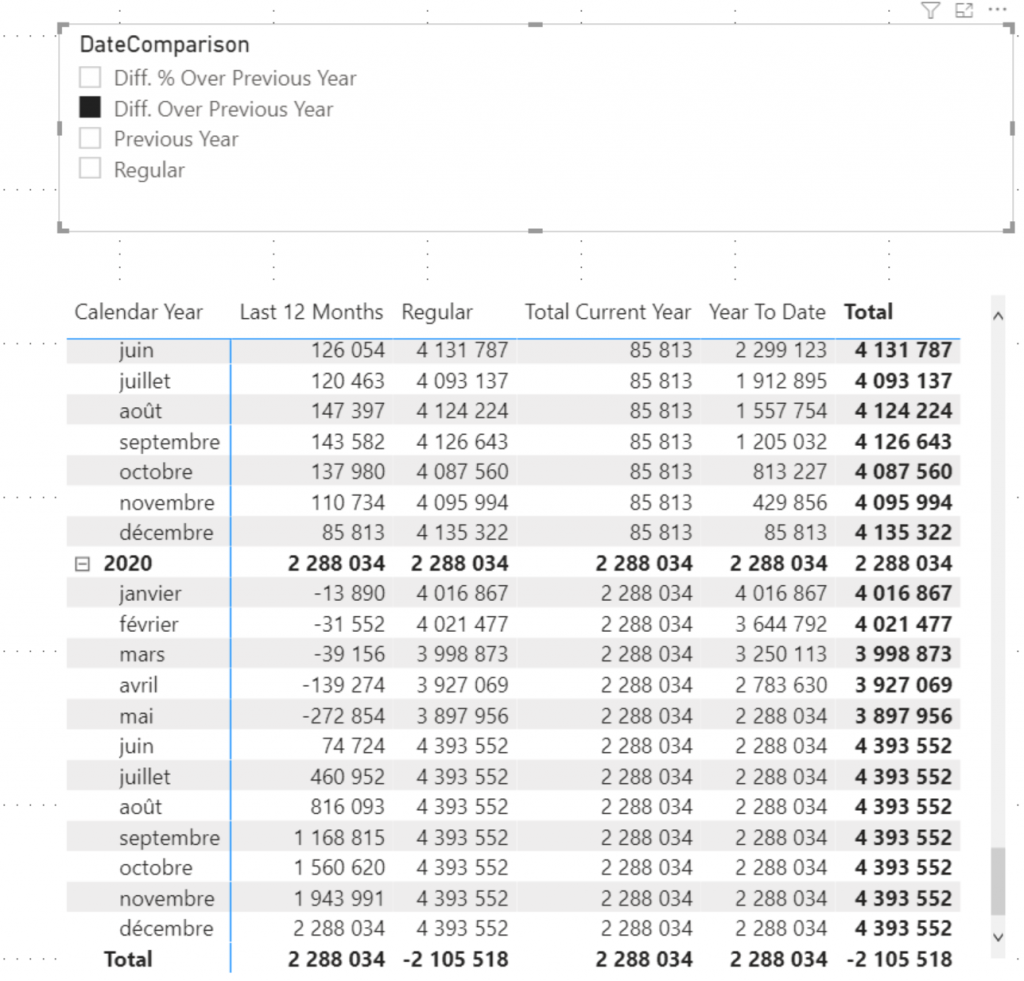
Le résultat est satisfaisant, on est bien capable de croiser les deux axes et d’obtenir un outil puissant d’analyse temporelle. Toutefois, on remarque assez vite les limites de maintenabilité de la solution (Il faut multiplier ce code par mesure). De plus, imaginons qu’après avoir déployé ce « template » sur 20 mesures je décide d’optimiser le template en utilisant par exemple des variables ( cela semblerait une bonne idée 😉 ) il me faudrait mettre à jour une quantité importante de code et le risque d’erreur est très important.
Avec les Calculation Groups
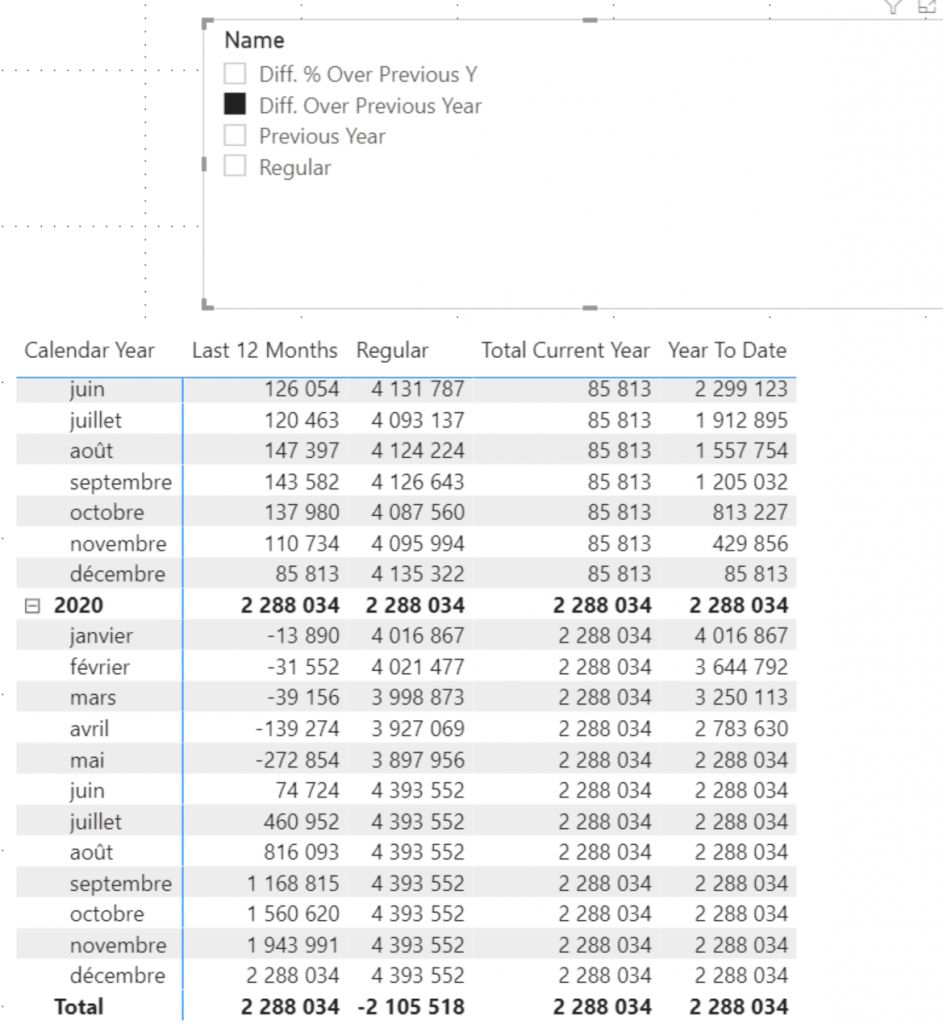
Depuis l’arrivée des Calculation Groups, c’est beaucoup plus simple, depuis Tabular Editor ou Visual Studio il est possible d’ajouter un Calculation Group et des Items contenant la règle de calcul à appliquer lors de leur sélection.
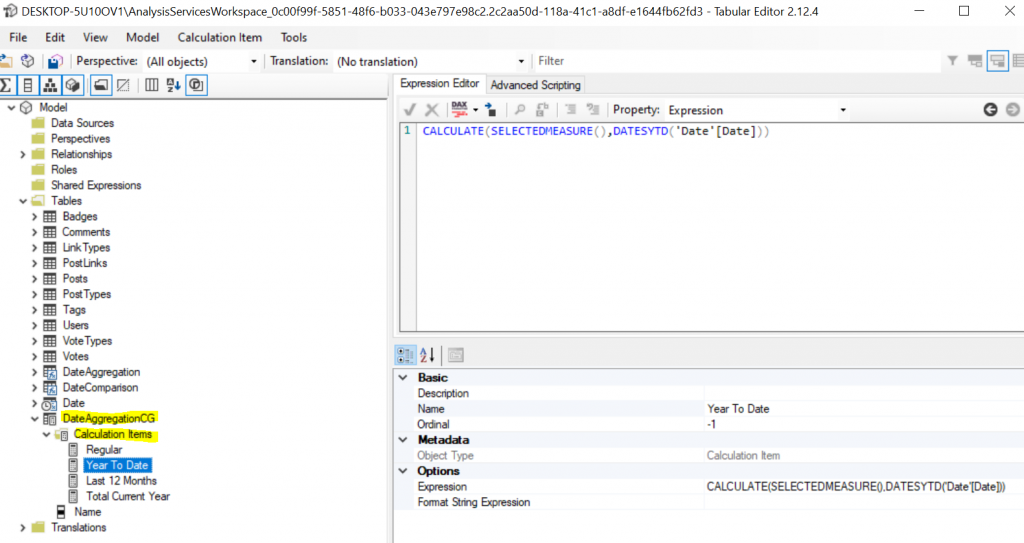
Les calculs sont identiques au SWITCH implémenté précédemment mais plutôt que d’utiliser une mesure statique [Nb Post] c’est SELECTEDMEASURE() qui est utilisé ce qui permet d’appliquer la règle de calcul à toute mesure évaluée lors de la sélection d’un ITEM.
Plus besoin de créer de table de paramétrage, le calculation item est auto porteur.
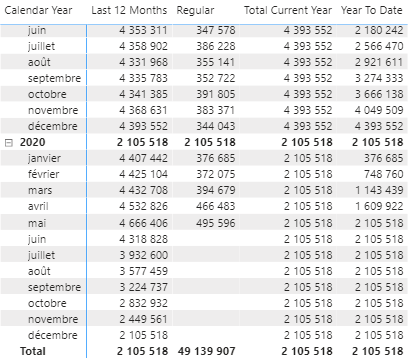
La puissance du Calculation Group est d’autant plus évidente que l’on implémente notre second axe d’analyse.
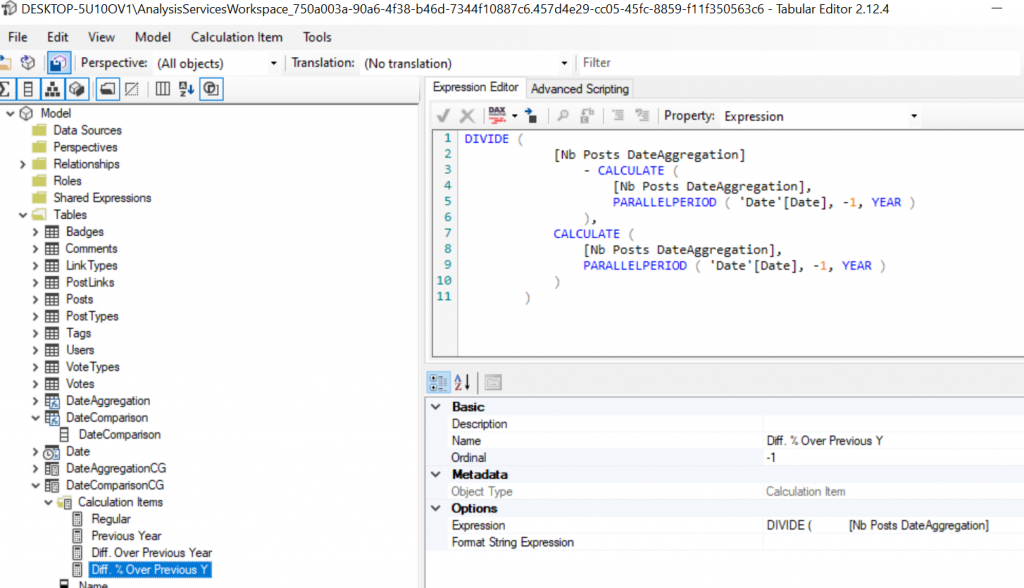
L’intérêt principal ici c’est qu’il n’y a plus besoin de faire de lien entre nos deux axes, les deux Calculation Groups propagent leurs contextes de filtres ainsi, si les deux sont utilisés leurs effets seront cumulés.
Impact sur les performances
Prenons une requête simple :
--SWITCH IMPLEMENTATION
EVALUATE
SUMMARIZECOLUMNS(DateAggregation[DateAggregation]
,'Date'[Calendar Year]
,'Date'[Month Name]
,"nb Post",[Nb Posts DateAggregation]
)
--CALCULATION GROUP IMPLEMENTATION
EVALUATE
SUMMARIZECOLUMNS(DateAggregationCG[Name]
,'Date'[Calendar Year]
,'Date'[Month Name]
,"nb Post",[Nb Posts]
)Côté storage engine, aucun impact, les deux requêtes se comportent strictement de la même manière.
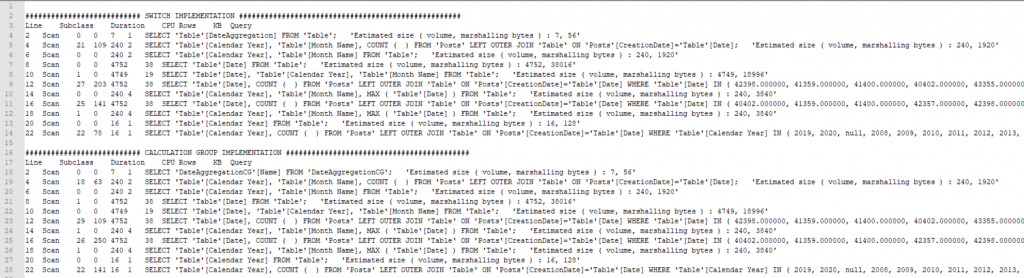
Côté Query Plan, ce n’est pas la même histoire, des différences existent ce qui laisse présager que dans certaines conditions, les performances pourraient varier.
Quid de l’utilisation des deux axes de notre Date Tool (DateAgg et DateComp) sur les performances ?
--SWITCH IMPLEMENTATION
EVALUATE
SUMMARIZECOLUMNS(DateAggregation[DateAggregation]
,'Date'[Calendar Year]
,'Date'[Month Name]
,FILTER('DateComparison','DateComparison'[DateComparison]="Diff. Over Previous Year")
,"nb Post",[Nb Posts DateComparison]
)
--CALCULATION GROUP IMPLEMENTATION
EVALUATE
SUMMARIZECOLUMNS(DateAggregationCG[Name]
,'Date'[Calendar Year]
,'Date'[Month Name]
,FILTER('DateComparisonCG','DateComparisonCG'[Name]="Diff. Over Previous Year")
,"nb Post",[Nb Posts]
)
Les requêtes au storage engine commencent à se démarquer et le Calculation Group prend les devants, avec une requête de moins et globalement moins d’utilisation CPU.
Cela n’est pas directement lié à l’implémentation du Calculation Group et il est très certainement possible en retravaillant le SWITCH initial (principalement en utilisant qu’une seule mesure) d’obtenir un plan assez équivalent, toutefois, force est de constatait que la simplicité d’implémentation du Calculation Group, permet de réaliser plus facilement des mesures efficaces.
Complexités induites par l’utilisation des Calculation Groups
Arrivé à ce Chapitre (et si vous avez eu le courage de tout lire), vous vous dites peut-être que le Calculation Group n’a que des avantages. En effet, la maintenance est infiniment facilité, et l’implémentation plus simple implique souvent des gains de performance. Toutefois, tout n’est pas rose au monde des Calculation Groups.
En effet, comme au temps des SCOPE en MDX plusieurs problèmes découlent de leur utilisation.
Toutes les mesures sont impactées lors de l’utilisation d’un Calculation Group. Et donc, lorsque vous avez un Calculation Group en filtre de page par exemple celui-ci va s’appliquer à toutes vos mesures (sauf indication contraire dans l’implémentation des items).
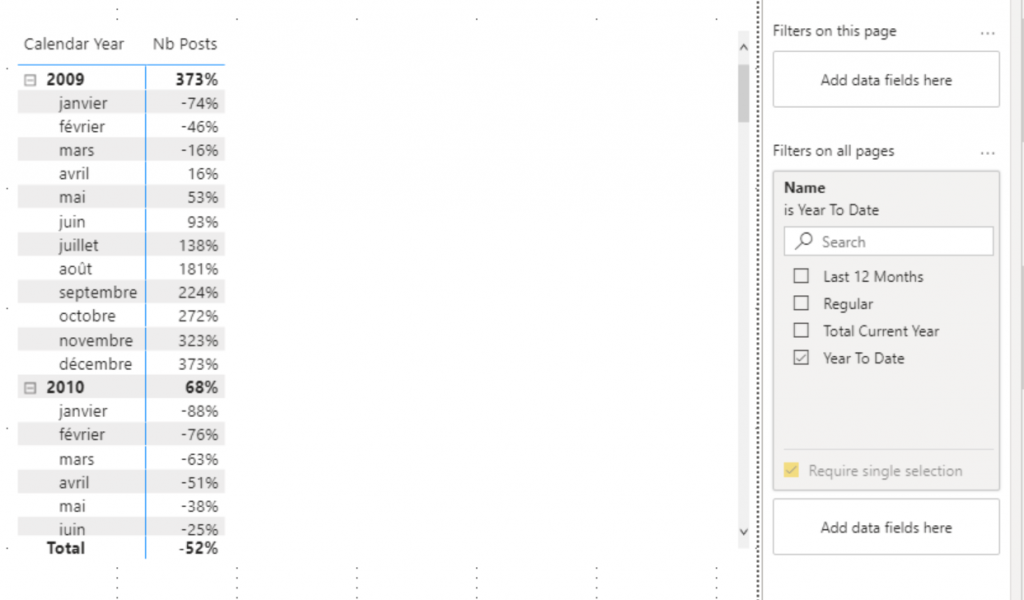
Lors de la création initiale du rapport cela semble évident et puis avec le temps, on créé une mesure qui ne doit pas s’afficher en YTD, qui ne fonctionne pas uniquement sur ce rapport sans que l’on comprenne pourquoi.
Il est aussi nécessaire de toujours penser à l’ordre d’évaluation des Calculation Groups. En effet, qu’en est t’il si j’ai un Calculation Group qui me permet de choisir un type d’agrégation en plus de celui me permettant de faire des Comparaisons temporelles.
Premiers Calculation Groups, on affiche deux comparaisons :
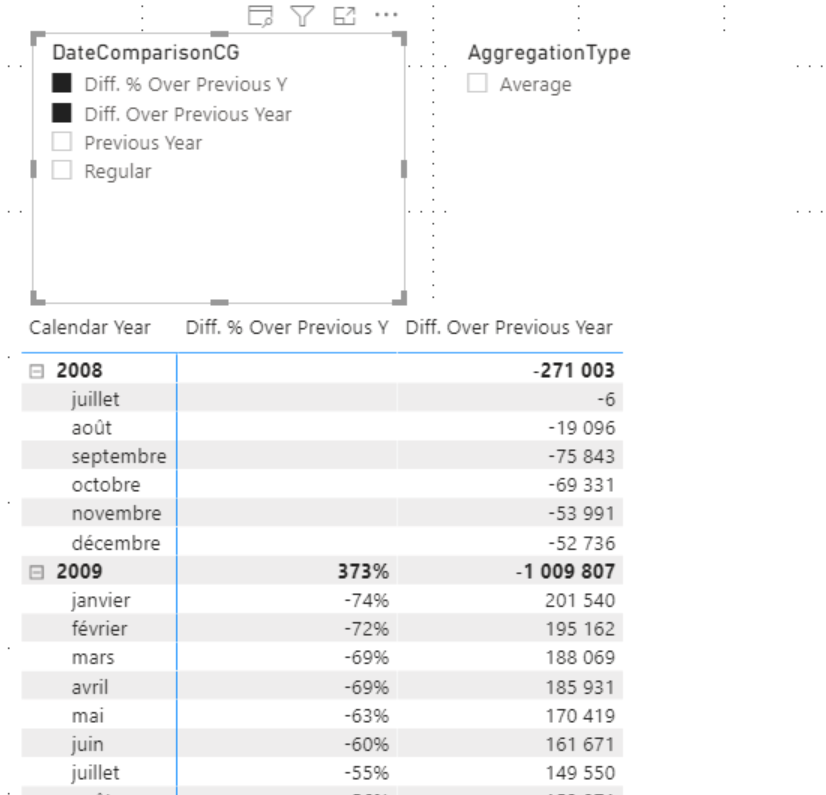
Par la suite on décide d’appliquer un Calculation Group qui permet de changer l’agrégation appliquée sur les mesures.
AVERAGEX(VALUES('Date'[Date]),SELECTEDMEASURE())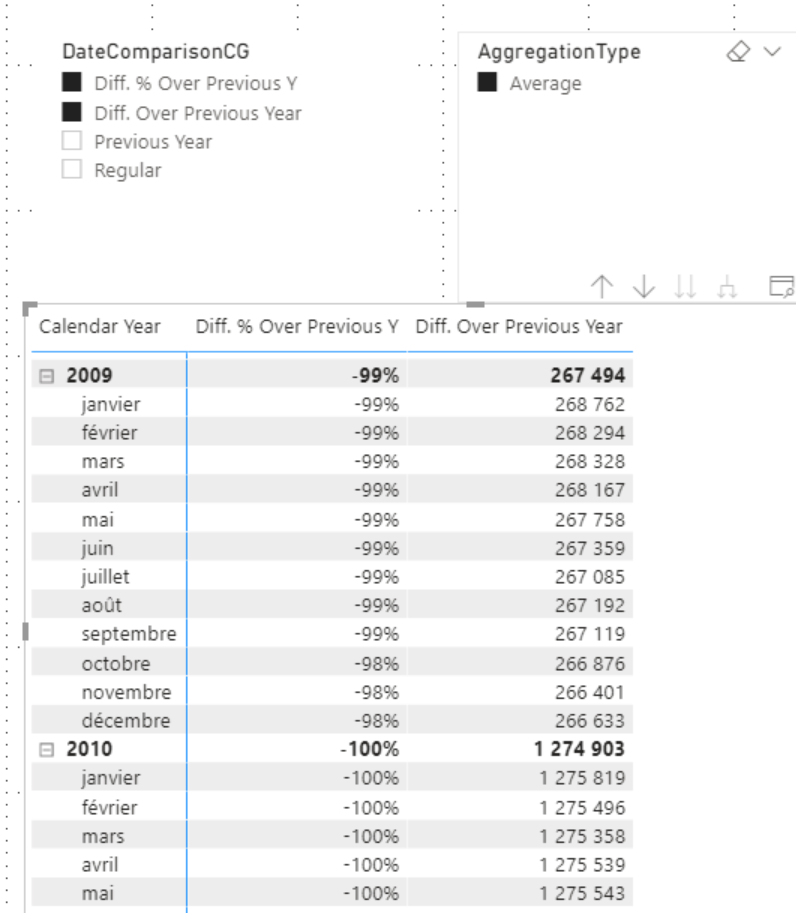
Le résultat ne semble pas satisfaisant, manifestement la moyenne n’est pas appliquée au bon moment, pour gérer l’ordre d’application des Calculation Groups, une propriété est disponible au niveau de celui-ci, la précédence. Les Calculation Groups sont évalués dans l’ordre croissant de leur précédence.
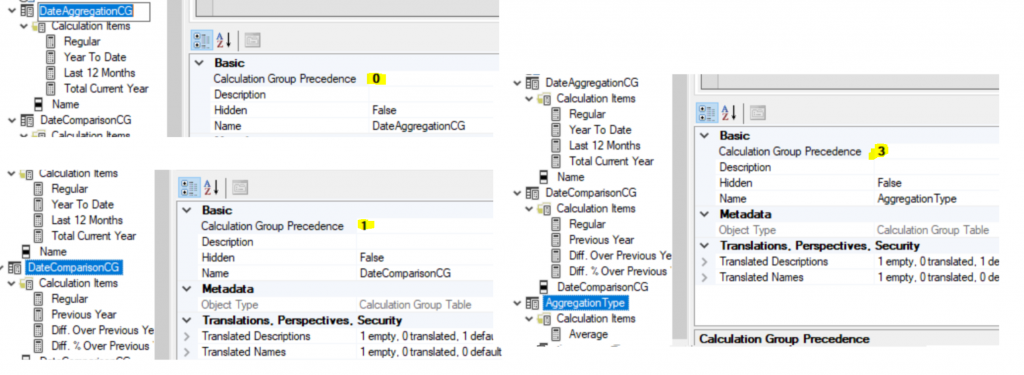
Par défaut, la précédence est incrémentée dans l’ordre de création des Calculation Groups.
Dans notre cas cela provoque l’évaluation de DateComparisonCG avant l’AggregationType. Ce qui n’est pas le comportement souhaité.
En passant DateComparaisonCG à 4.
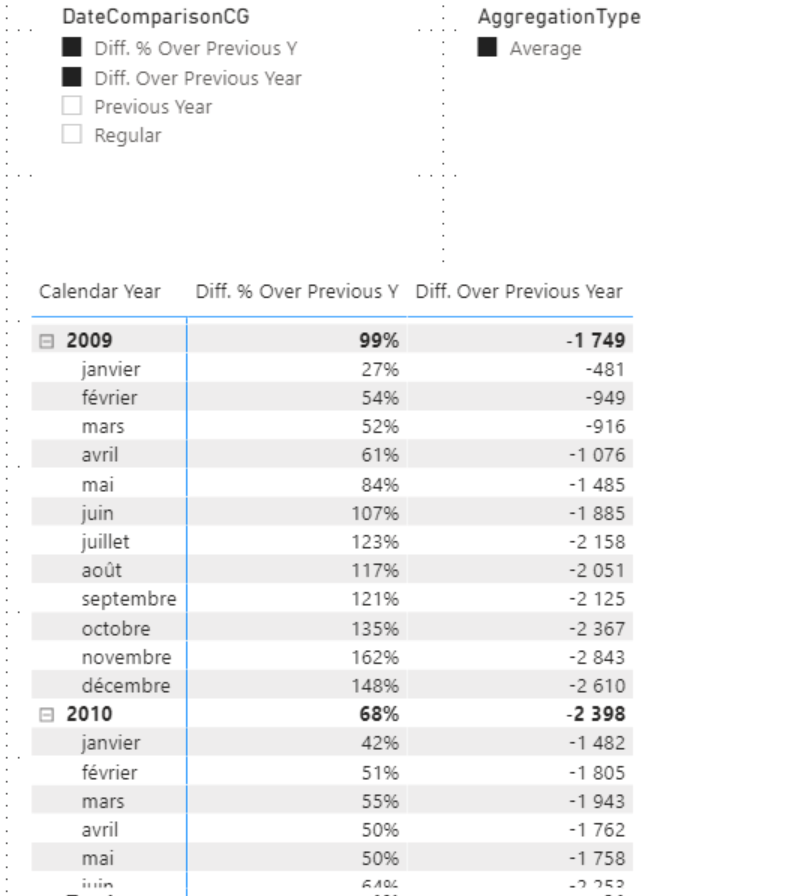
Le résultat change complètement.
Avec ces deux exemples et en imaginant un modèle avec 4, 5, 10 ou 30 Calculation Groups, vous imaginez les problèmes qu’il est possible de rencontrer et à quel point il est important de s’astreindre à quelques règles comme :
- Limiter au maximum la complexité des Calculation Groups
- Limiter leur nombre au sein d’un même modèle surtout si leur champs d’application est large
En conclusion, comme les SCOPE du temps du MDX les capacités offertes par les Calculation Groups sont énormes (tout n’est pas dans ce petit article). Toutefois, si ceux-ci sont puissants ils sont aussi difficiles à comprendre pour l’utilisateur final et peuvent rentre complexe l’utilisation de votre modèle. Il faudra donc les utiliser dans un cadre spécifique en complément d’un modèle bien nommé, bien modélisé (en étoile) et sur des cas d’usages simples.