◀️ C’est quoi l’interopérabilité et la réversibilité ?
Il s’agit de deux concepts que les éditeurs logiciels et les plateformes de cloud voudraient bien que l’on ignore.
📚 Que dit Wikipédia :
L’interopérabilité est la capacité que possède un produit ou un système, dont les interfaces sont intégralement connues, à fonctionner avec d’autres produits ou systèmes existants ou futurs et ce sans restriction d’accès ou de mise en œuvre.
La réversibilité en informatique est la possibilité, pour un client ayant sous-traité son exploitation à un infogérant, de récupérer ses données à l’issue d’un contrat. On parle de clause de réversibilité.
Autrement dit, ces concepts, assez sains, incitent à se poser la question de l’adhérence à une solution ou un fournisseur.
👀 Prenons un exemple
Je propose régulièrement l’architecture Analytics end-to-end with Azure Synapse de Microsoft , car celle-ci est flexible et pleine d’avantages.
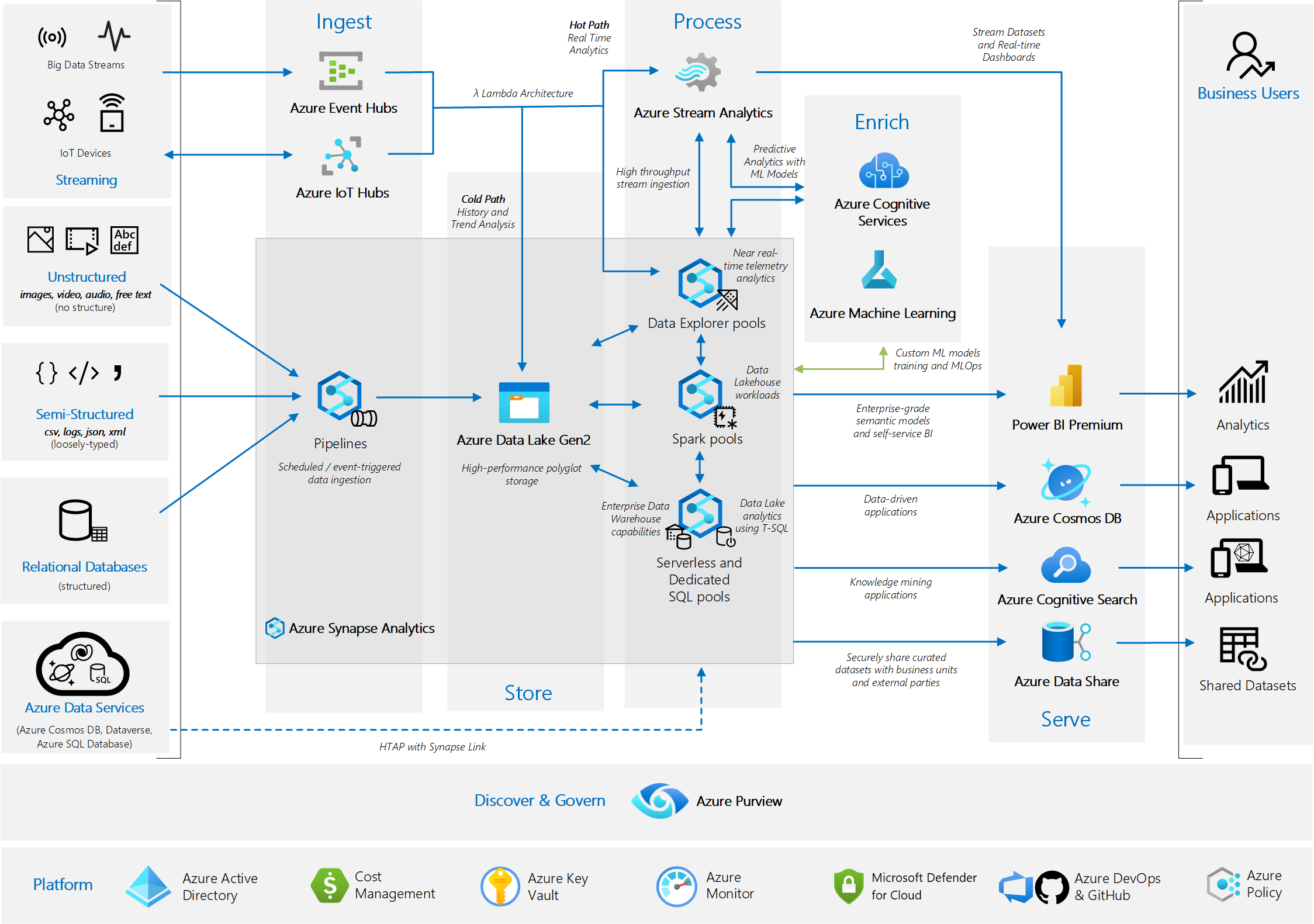
Celle-ci est composée de :
- Ingestion avec Azure Synapse Pipeline
- Traitement avec SQL Pool Dedicated, Spark Pools ou Data Explorer Pools
- Présentation avec Power BI Premium
Sur cette architecture, comment sommes-nous positionnés en terme de réversibilité et d’interopérabilité ?
- Ingestion :
- Azure Synapse Pipeline ne peut être exécuté que sur Azure, et uniquement en utilisant Azure Synapse Pipeline. Par ailleurs, nous n’avons aucune idée du fonctionnement sous-jacent à cet outil, c’est intégralement à la main de Microsoft.
❌ Cette solution n’est donc ni réversible, ni interopérable.
- Azure Synapse Pipeline ne peut être exécuté que sur Azure, et uniquement en utilisant Azure Synapse Pipeline. Par ailleurs, nous n’avons aucune idée du fonctionnement sous-jacent à cet outil, c’est intégralement à la main de Microsoft.
- Traitement :
- SQL Pool Dedicated, il s’agit là du MPP de Microsoft, qui est uniquement disponible sur Azure. Par ailleurs, nous n’avons aucune idée du fonctionnement sous-jacent à cet outil, c’est intégralement à la main de Microsoft. Il n’y a pas de solution de sauvegarde exportable en dehors du cadre de Synapse.
❌ Cette solution n’est donc ni réversible, ni interopérable. - Spark Pools, il s’agit là d’une implémentation de Spark disponible sur Azure, toutefois ce moteur de traitement étant basé sur Spark, un script fonctionnant sur Azure Spark Pool pourrait fonctionner sur un moteur Spark de la même version. Cette implémentation de Spark propre à Microsoft n’est toutefois pas proposée en open-source, il est donc difficile d’estimer si certaines fonctionnalités seront compatibles ou non. De plus aucun endpoint Spark n’est aujourd’hui accessible sur Spark Pool.
❌ Cette solution n’est donc ni réversible, ni interopérable. - Data Explorer est une solution d’analyse de données uniquement disponible sur Azure. Par ailleurs, nous n’avons aucune idée du fonctionnement sous jacent à cet outil, c’est intégralement à la main de Microsoft.
❌ Cette solution n’est donc ni réversible, ni interopérable.
- SQL Pool Dedicated, il s’agit là du MPP de Microsoft, qui est uniquement disponible sur Azure. Par ailleurs, nous n’avons aucune idée du fonctionnement sous-jacent à cet outil, c’est intégralement à la main de Microsoft. Il n’y a pas de solution de sauvegarde exportable en dehors du cadre de Synapse.
- Présentation :
- Power BI Premium est une solution SaaS, même si celle-ci comporte des éléments permettant une connectivité depuis de multiple outils grâce aux XMLA Endpoint, un jeu de données Power BI Premium ne peut s’exécuter que sur le service de Microsoft.
❌ Cette solution n’est donc ni réversible, ni interopérable.
- Power BI Premium est une solution SaaS, même si celle-ci comporte des éléments permettant une connectivité depuis de multiple outils grâce aux XMLA Endpoint, un jeu de données Power BI Premium ne peut s’exécuter que sur le service de Microsoft.
L’exercice d’analyse de la solution sous le prisme de la réversibilité et de l’interopérabilité met donc en avant que ce n’est clairement pas le point fort de cette solution.
Cela n’enlève en rien les nombreuses qualités de cette architecture :
- Excellente intégration dans l’écosystème Azure (Permission, PaaS)
- Pas d’infrastructure à gérer, simplicité de l’opération de la solution
- Coût avantageux
- Time-to-market excellent
Par contre, cette architecture demeure sur Microsoft Azure et il est impossible d’envisager une migration de celle-ci ailleurs.
La question de la réversibilité et de l’interopérabilité va souvent se présenter comme cela, un combat entre simplicité et propriété. Malheureusement, comme de nombreux autres sujets, il n’y aura jamais de réponse absolue, mais plutôt un consensus à trouver en fonction de votre écosystème et des volontés liés à votre entreprise.
L’open-source tend à proposer des solutions plus interopérables, mais se heurte de fait à des problèmes de financement, de responsabilité, et de complexité à opérer. Ces problèmes que les fournisseurs Cloud ou certains éditeurs règlent souvent en intégrant des outils open-source et en les commercialisant, tout en refermant par la même occasion le code et la capacité à faire tourner les traitements ailleurs que chez eux pour s’assurer un retour sur investissement.
⁉️ Comment rendre une architecture d’avantage réversible et interopérable ?
🔮 Se projeter sur un scénario de migration
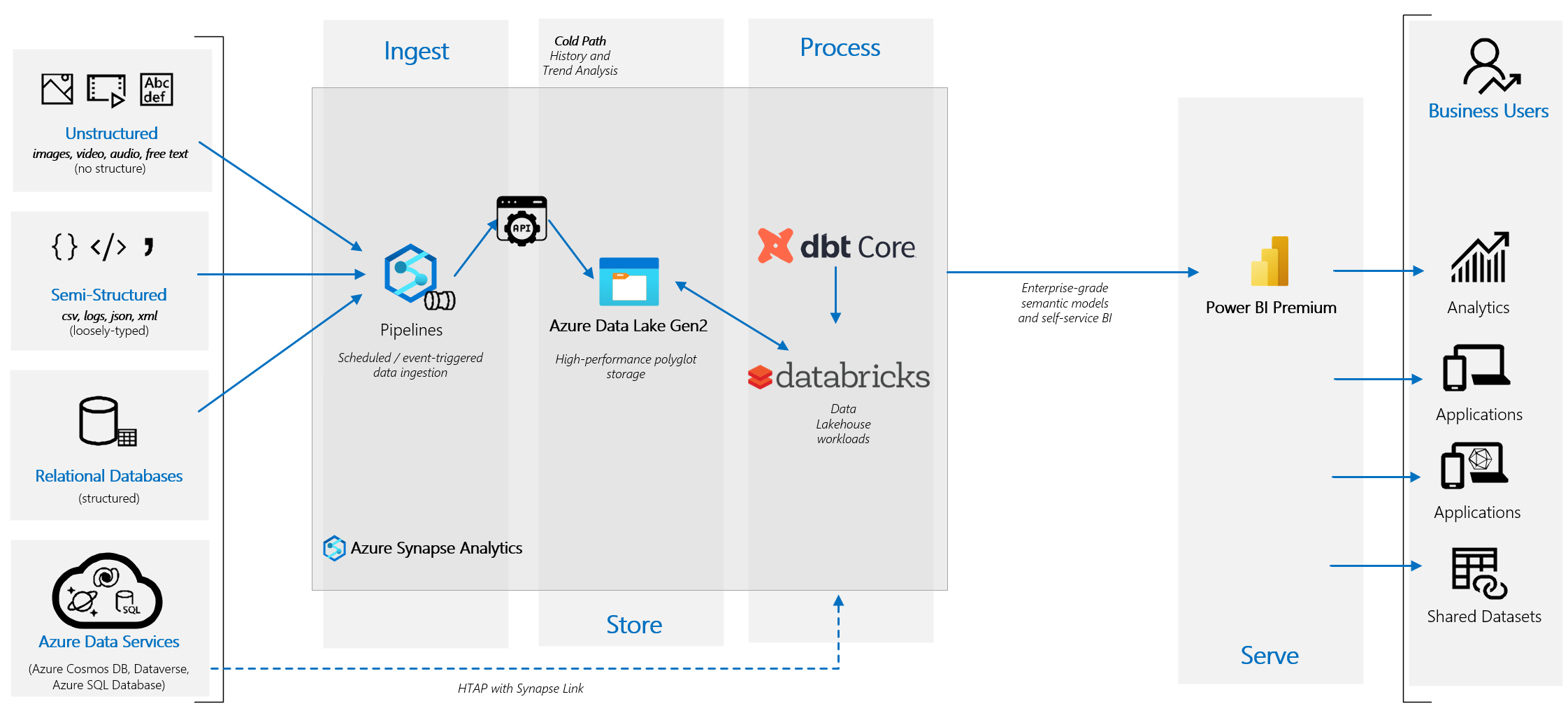
Prenons notre architecture Azure Synapse Pipeline > Synapse SQL Pool Dédié > Power BI Premium. Que se passe t’il si demain, Microsoft Azure est banni d’un usage Européen et qu’il est souhaitable de migrer chez OVH Cloud.

Azure Synapse Pipeline permet de réaliser les ingestions dans la plateforme d’analyse de données. C’est un service simple et efficace avec un retour sur investissement incroyable. Il ne s’agit donc pas là de se passer de ce service, mais plutôt de découpler l’ingestion de l’utilisation de celui-ci.
La solution la plus réversible serait sûrement l’utilisation d’un ETL qui puisse s’exécuter n’importe où et idéalement pouvoir s’exécuter dans un container docker comme Talend. Toutefois cela représente un investissement tant sur les licences Talend que sur la gestion d’un environnement de containerisation.
Je vais donc privilégier la mise en place d’une surface agnostique d’ingestion qui me permet de référencer mes flux à ingérer (et donc d’identifier l’effort de migration à prévoir et éventuellement l’automatiser) et d’ajouter des métadonnées. Partons par exemple sur la mise en place d’une API d’ingestion en HTTP qui pourra être utilisée par Azure Synapse ou n’importe quel autre outil qui sait appeler un endpoint HTTP pour pousser des fichiers.
Le format de stockage des données, est certainement l’élément le plus crucial d’un scénario de réversibilité, c’est d’ailleurs ce qui a fait encore le succès du CSV aujourd’hui en dépit de ses nombreux inconvénients. Heureusement l’open source est venu à notre aide ces dernières années avec l’arrivée du Parquet, Hudi, Iceberg, Delta et autres qui nous offrent des solutions de stockage efficaces et interopérables. Pour pouvoir profiter de ces formats dans notre architecture nous partirons donc sur un mélange de Synapse Spark Pool et SQL Serverless en profitant du type de fichier Delta.io.
Le traitement des données, la couche qui contient toutes nos transformations, nos règles métier et donc la complexité de notre solution. Nous l’avons vu pour pouvoir profiter d’un format de stockage interopérable, il nous est uniquement possible d’utiliser Spark Pool et SQL Serverless. Mais comment réaliser des transformations qui fonctionneront aussi bien sur Azure Spark Pool, SQL Serverless, ou sur la solution de traitement qui sera disponible sur notre environnement OVH. Certainement pas avec Azure Synapse Data Flow qui est la solution la plus fermée disponible et qui bien qu’utilisant Spark, utilise un langage propriétaire réservé à Azure Synapse. Nous nous tournerons vers le projet open source dbt Core qui permet d’exécuter un même script SQL + Jinja sur de multiples systèmes de traitement tels que : Spark, SQL Server, Synapse SQL Pool, Snowflake ( Pas très réversible / Intéropérable snowflake par ailleurs : When data is loaded into Snowflake, Snowflake reorganizes that data into its internal optimized, compressed, columnar format. Snowflake stores this optimized data in cloud storage. Snowflake manages all aspects of how this data is stored — the organization, file size, structure, compression, metadata, statistics, and other aspects of data storage are handled by Snowflake. The data objects stored by Snowflake are not directly visible nor accessible by customers; they are only accessible through SQL query operations run using Snowflake.) …
Cette couche DBT va nous permettre de grandement diminuer notre adhérence, toute notre logique métier, nos transformations pouvant s’exécuter sur le moteur de notre choix, dans le cloud ou On-Premise.
La présentation, en continuant à utiliser Power BI, pas le choix, en cas de migration nécessaire il faudra tout recommencer. La solution On-Premise de Microsoft n’étant pas iso-fonctionnelle avec ce que propose la version cloud, il ne sera pas possible de simplement migrer l’existant de PowerBI.com vers une instance de Power BI Report Server.
🧬 L’architecture résultante
Conclusion
Il est nécessaire de bien comprendre les risques de la perte de contrôle sur ses processus. Les revendeurs de solutions ont pour objectif majeur de nous rendre captif (Salesforce, SAP, Azure, AWS, Google…) et ce afin de s’assurer des revenus qui sont souvent mérités de par leurs investissements et la simplification / optimisation de leurs solutions PaaS / SaaS. Il ne s’agit pas de ne jamais profiter des avantages de ces solutions, mais plutôt de trouver des solutions qui diminueront la difficulté de migration si d’aventure, pour des raisons légales, commerciales, il était nécessaire de déplacer ses architectures.
Avec Matthieu Roy nous vous préparons une présentation d’implémentation de l’architecture ci-dessus en mettant l’accent sur dbt Core pour ce meetup des Gentils Développer Data Platform.



2 Comments
Salut Charles-Henri, article très très intéressant, merci pour cette lecture!
Effectivement, ne pas rester captif d’un environnement propriétaire ça va être un bel enjeu pour les années à venir. Après tout nous ne sommes que des locataires (tenant) 🙂
[…] ouverture est poussée par une quête de reversibilité et de vision stratégique lié à mon poste. Je suis par ailleurs extrêmement intéressé par des […]