Pour faire suite à mon teaser et presque 4 mois après le post de celui-ci voici mon expérience avec Hadoop on premise sur Linux (Ubuntu 12.04 LTS pour être précis).
Introduction
Bon, installer Hadoop c’est la galère soyons clair, peu de documentation, des versions différentes avec des spécificités, ce qui rend tout ça encore plus difficile.
Afin de réussir mon installation j’ai suivi plusieurs blogs (la documentation officielle disponible ici étant assez succincte et pas très intuitive.)
- http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/ClusterSetup.html
- http://raseshmori.wordpress.com/2012/10/14/install-hadoop-nextgen-yarn-multi-node-cluster/
Le problème voyez-vous, c’est que même en suivant ces articles à la lettre sur la version 2.2.0 cela ne fonctionne pas, en cause des changements dus aux nouvelles versions (NodeManager par nœud du cluster …)
Bref toute la difficulté tourne autour de la configuration des différents fichiers, c’est pour cela que je vais mettre l’accent sur ceux-ci et vous laisser lire le post de Rasesh Mori pour les détails.
A. Configuration du master
Fichier /etc/hosts
127.0.0.1 localhost 192.168.0.13 hadoop0 192.168.0.131 hadoop1 192.168.0.31 hadoop2 192.168.0.132 hadoop3 192.168.0.133 hadoop4 192.168.0.134 hadoop5 192.168.0.135 hadoop6 192.168.0.136 hadoop7 192.168.0.137 hadoop8 192.168.0.138 hadoop9
Attention sur Ubuntu vous avez par défaut une ligne 127.0.1.1 avec le nom de la machine … ceci cause le bug suivant : https://wiki.apache.org/hadoop/ConnectionRefused Vous pouvez passer longtemps à chercher quel est le problème alors pensez à enlever cette ligne 🙂
Mes fichiers de configuration Hadoop Yarn 2.2.0 sont présents chez moi dans le dossier /usr/local/hadoop, mes fichiers de configuration sont donc dans /usr/local/hadoop/etc/hadoop/
Fichier core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://192.168.0.13:9000</value> </property> </configuration>
192.168.0.13 est l’adresse de ma machine master, comme vous l’avez surement remarqué au vu de mon fichier /etc/hosts, j’aurais pu remplacer l’ip par hadoop0.
Fichier hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/media/Data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/media/Data/hdfs/datanode</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
Vous noterez que c’est ici que l’on définit deux paramètres importants : dfs.replication qui spécifie à hdfs combien de réplicats de données doivent être présents sur notre cluster, et dfs.datanode.data.dir qui spécifie l’emplacement de nos données (de notre partition hdfs finalement).
Fichier yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.0.13:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.0.13:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.0.13:8040</value> </property> <property> <name>yarn.nodemanager.address</name> <value>192.168.0.13:8050</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>192.168.0.13:8060</value> </property> </configuration>
Fichier slaves
localhost 192.168.0.31 192.168.0.131 192.168.0.132 192.168.0.133 192.168.0.134 192.168.0.135 192.168.0.136 192.168.0.137 192.168.0.138
Même remarque qu’au dessus sur l’utilisation des IP que j’aurais pu remplacer par les noms de machine.
B. Configuration d’un esclave
La configuration d’une machine esclave est assez similaire à notre machine maître mis à part que la majorité des fichiers de configuration vont pointer vers le master (NodeManager exclus)
Fichier /etc/hosts
127.0.0.1 localhost 192.168.0.13 hadoop0 192.168.0.131 hadoop1 192.168.0.31 hadoop2 192.168.0.132 hadoop3 192.168.0.133 hadoop4 192.168.0.134 hadoop5 192.168.0.135 hadoop6 192.168.0.136 hadoop7 192.168.0.137 hadoop8 192.168.0.138 hadoop9
Fichier core-site.xml
<configuration> <property> <name>fs.default.name</name> <value>hdfs://192.168.0.13:9000</value> </property> </configuration>
Oui oui c’est bien l’ip de notre machine maître qu’il faut mettre ici.
Fichier hdfs-site.xml
<configuration> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/media/Data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/media/Data/hdfs/datanode</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
Fichier yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>192.168.0.13:8025</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>192.168.0.13:8030</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>192.168.0.13:8040</value> </property> <property> <name>yarn.nodemanager.address</name> <value>192.168.0.132:8050</value> </property> <property> <name>yarn.nodemanager.localizer.address</name> <value>192.168.0.132:8060</value> </property> </configuration>
Attention, ici il faut changer les configurations de yarn.nodemanager.address et yarn.nodemanager.localizer.address car depuis la version 2.2 (et ça ce n’est pas spécifié sur nos articles précédents !!!) il y a un NodeManager par noeud du cluster.
Fichier slaves
localhost
C. L’attaque des clones !
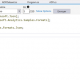
L’avantage lorsque vous êtes virtualisé et que vous avez configuré un master et un esclave, vous pouvez cloner l’esclave à l’infini pour arriver à votre taille de cluster désiré.
- Cloner l’esclave dans hyper-v de la manière qui vous convient, personnellement, je copie / colle le VHD et je recrée une machine virtuelle. Sachant que linux + hadoop + hive + pig c’est 15 Go chez moi j’aurais d’ailleurs pu éviter d’installer l’interface graphique de Linux ce qui m’aurait économiser de l’espace.
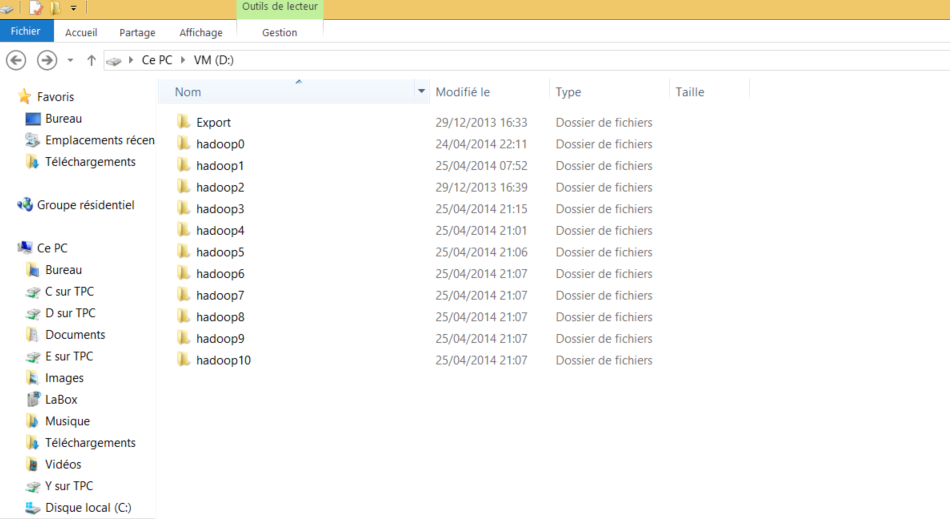
Nos petites VM bien au chaud ! - Première chose à faire : fixer l’ip de chaque machine, cela nous permettra une connexion simple en SSH par la suite. (Perso je le fais de manière graphique dans mon ubuntu c’est mal mais bon je suis consultant sql server MICROSOFT vous vous souvenez ?) http://www.wikihow.com/Assign-an-IP-Address-on-a-Linux-Computer
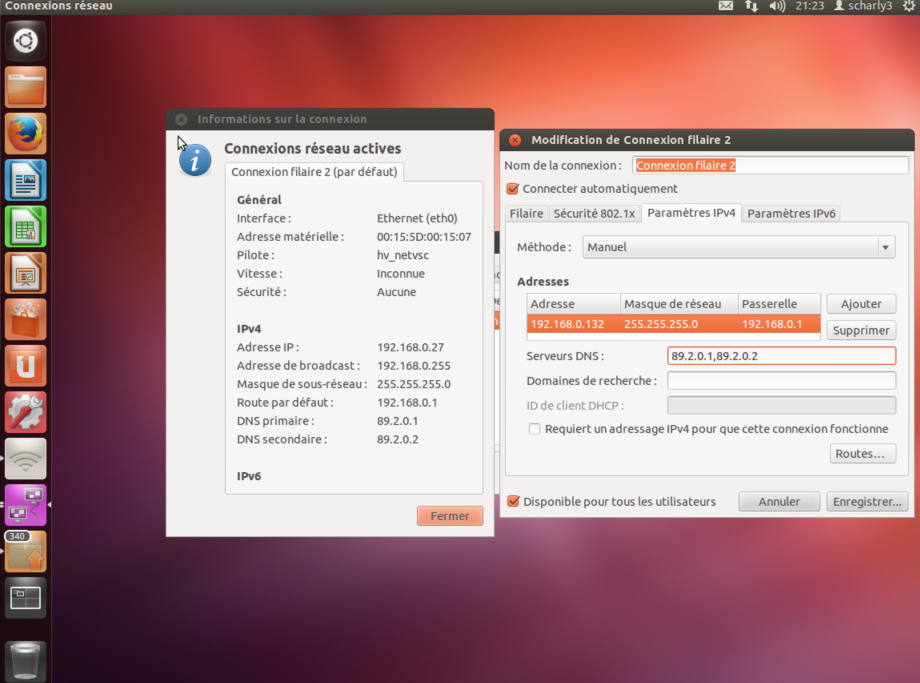
- Connectons-nous donc maintenant en SSH, perso j’utilise Putty, un vestige de mes années de DUT Informatique de Limoges.
Forcément étant donné que je suis sur un clone, mes comptes / installations / … sont déjà là et ça c’est cool, surtout quand on se rappelle comment on a galéré à faire nos premières installations !
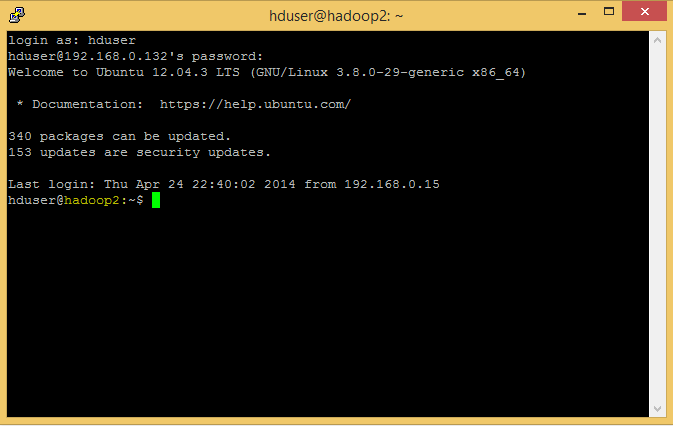
Et là on voit le problème tout de suite, la machine s’appelle hadoop2 (je suis parti d’hadoop2 pour faire mes clones) il faut donc faire quelques modifications. - Changer le hostname
sudo hostname hadoop3
(parce que là c’est hadoop3 la machine sur hadoop4 je vais mettre 4 … )
- Changer le hostname dans le fichier hostname
sudo nano /etc/hostname
Puis remplacer hadoop2 par hadoop3 dans le fichier.
(Oui j’utilise nano et pas vi … lancez moi des cailloux allez y ! MICROSOFT vous vous souvenez ?) - Maintenant il va falloir autoriser hadoop3 à se connecter à hadoop0 (le master) en ssh et autoriser hadoop0 à se connecter sur hadoop3.Sur hadoop3 :
cat ~/.ssh/id_rsa.pub | ssh hduser@192.168.0.13 'cat >> .ssh/authorized_keys'
Sur Hadoop0 :
cat ~/.ssh/id_rsa.pub | ssh hduser@192.168.0.132 'cat >> .ssh/authorized_keys'
Encore une fois j’utilise des IP, vous auriez pu jouer avec des noms de machines à condition d’éditer correctement les fichiers /hosts de celles-ci.
- Bon on est presque au bout, il nous faut maintenant supprimer le dossier de notre datanode car celui-ci est corrompu.
rm -rf /media/Data/hdfs/datanode/
Ceci afin d’éviter de se prendre le message d’erreur suivant lors du lancement du datanode :
java.io.IOException: Incompatible clusterIDs in /media/Data/hdfs/datanode: namen ode clusterID = CID-bebf5729-2dea-4328-b687-29c4f90bd232; datanode clusterID = C ID-7f49d400-0884-4c96-be52-5c7f725bedaa
- Last but not least, mettre à jour notre machine master afin de lui notifier l’existence de ce nouveau nœud :
nano /usr/local/hadoop/etc/hadoop/slaves
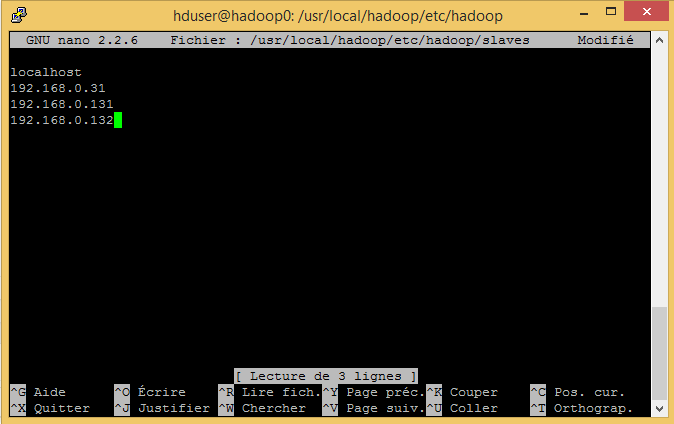
- On peut maintenant lancer les commandes suivantes sur notre master afin de lancer le Datanode et le DatanodeManager sur notre nouveau noeud :
sbin/hadoop-daemons.sh start datanodesbin/yarn-daemons.sh start nodemanager
Et voilà le travail, mon nœud est bien ajouté à mon cluster :
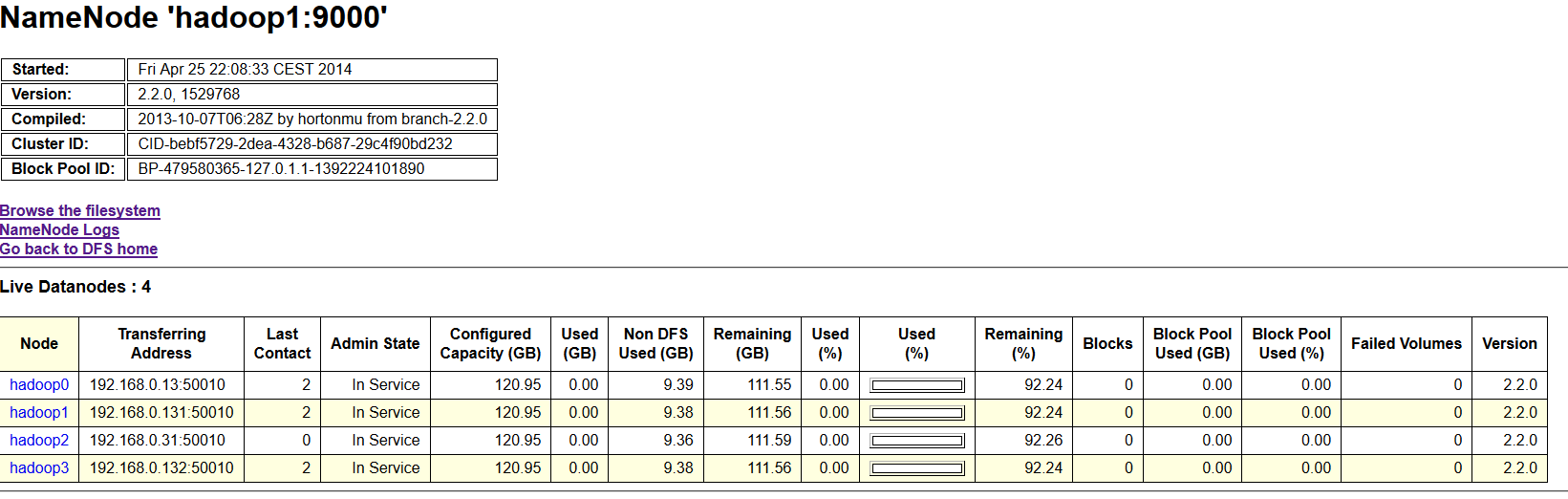
Il ne me reste plus qu’à réaliser ces actions 6 fois.
Après la configuration des 6 machines restantes voici mon cluster dans hyper-v
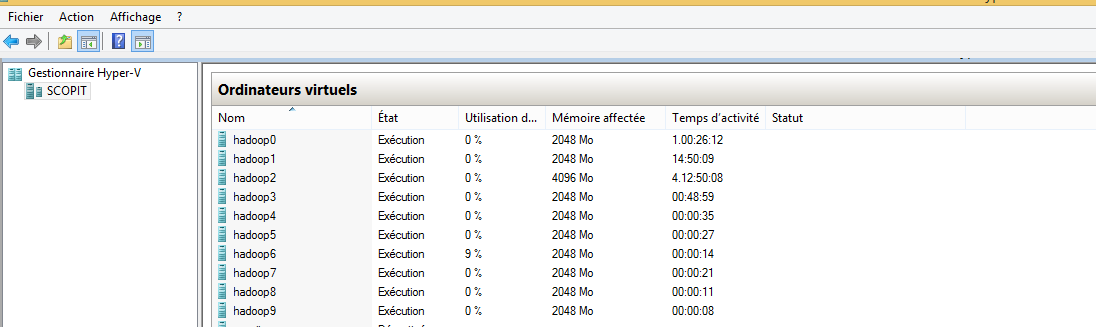
Et dans la console hdfs
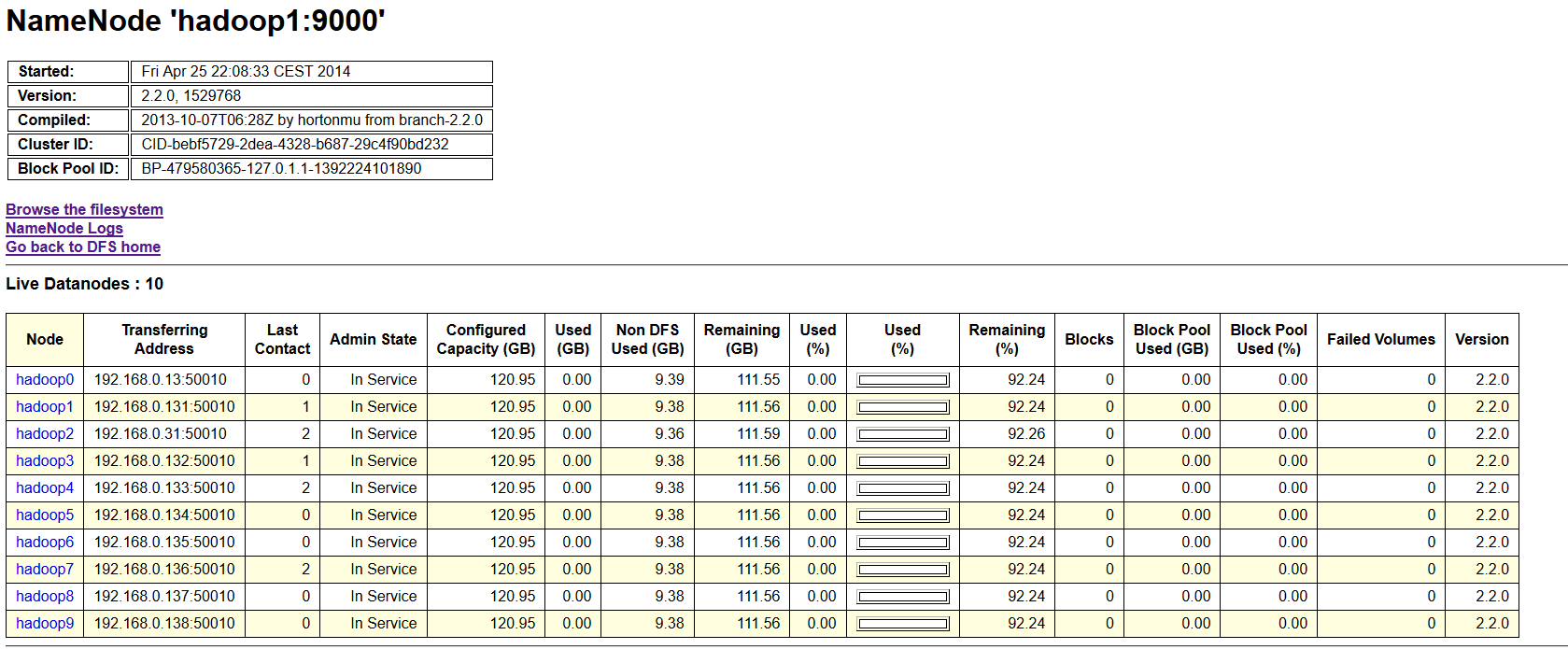
La partie configuration de notre cluster Hadoop est maintenant terminée, n’hésitez pas à lire l’article sur les tests de performance (A venir).