Imaginez que vous ayez fait votre gestion d’inconnu dans toutes vos dimensions (personnellement j’aime bien faire cela dans un post deployment script SSDT) vous avez donc dans vos dimensions des lignes de la forme :
SELECT * FROM DimCountry
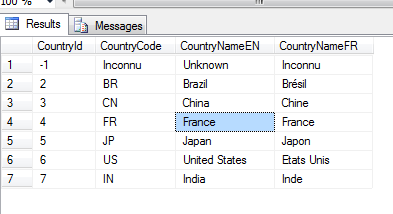
Parfait, vous avez rempli vos 30 dimensions et là le métier se réveille et vous annonce comme une fleur … en fait on va plutôt mettre Non affecté et Not affected … Faire la modification dans SSDT c’est facile un petit CTRL + H fera l’affaire par contre j’ai déjà remplie mes tables de faits il faudra donc faire 30 UPDATE pour mettre à jour ce qui est déjà déployé ? Coté feignant oblige voici une solution cra cra basée sur mon précédent article : [T-SQL] Rechercher une valeur dans toutes les tables et colonnes d’une base
DECLARE @RQForEachTable NVARCHAR(MAX) = ‘
DECLARE @RQSQL varchar(MAX)
DECLARE @Column varchar(255)
DECLARE columnCursor CURSOR FOR
SELECT C.name FROM sys.columns C
INNER JOIN sys.objects O
ON C.object_id = O.object_id
WHERE type_desc= »USER_TABLE »
AND C.object_id=OBJECT_ID( »? »)
OPEN columnCursor;
FETCH NEXT FROM columnCursor
INTO @Column;
— Check @@FETCH_STATUS to see if there are any more rows to fetch.
WHILE @@FETCH_STATUS = 0
BEGIN
— This is executed as long as the previous fetch succeeds.
FETCH NEXT FROM columnCursor
INTO @Column;
SET @RQSQL= »UPDATE ? SET [ »+ @Column + »] = CASE WHEN CAST( »+@Column+ » AS NVARCHAR) = » »Inconnu » » THEN » »Non affecté » » ELSE » »Not affected » » END WHERE CAST([ »+ @Column + »] AS NVARCHAR) IN ( » »Inconnu » », » »Unknown » ») »
PRINT @RQSQL
–exec sp_sqlexec @RQSQL
END
CLOSE columnCursor;
DEALLOCATE columnCursor;
‘
EXEC sp_MSforeachtable @RQForEachTable
–Update du 03/05/2014
Suite à un retour de Sarah (Schtroumpfette DBA), sur l’utilisation d’un curseur et à une proposition très élégante à base de FOR XML PATH, IIF, et CONCAT, voici une mise à jour, Merci beaucoup Sarah !
DECLARE @DynSQL VARCHAR(MAX)
SELECT @DynSQL = (
SELECT CONCAT('UPDATE ', S.TABLE_NAME, ' SET ', S.COLUMN_NAME, ' = ', 'IIF(', S.COLUMN_NAME, ' = ''Inconnu'', ''Non affecté'', ''Not affected'') ', ' WHERE ', S.COLUMN_NAME, ' IN (''Non affecté'', ''Not affected''); ', CHAR(10))
FROM INFORMATION_SCHEMA.COLUMNS S
WHERE OBJECTPROPERTY(OBJECT_ID(S.TABLE_NAME), 'IsUserTable') = 1
AND S.DATA_TYPE IN ('VARCHAR', 'NVARCHAR', 'CHAR', 'NVARCHAR')
FOR XML PATH('')
)
EXEC sp_sqlexec @DynSQL
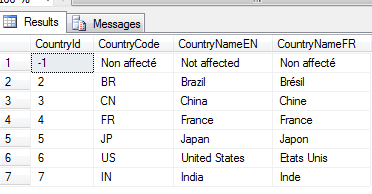
Et voilà le travail :
Et ceci sur nos 30 Tables …



2 Comments
de mon coté pour ces tables de codifications je mets ça dans une seule table du type ID,Code,FR,EN,nom_dimension. Je fais ensuite des vues dessus en filtrant à chaque fois sur la dimension concernée et la ligne de gestion -1 ce qui fait que je n’ai qu’une table à modifier pour que ça se répercute.
Mettre toutes les références inconnues dans une seule table a le seul avantage de simplifier la gestion d’insertion et de mise à jour de ces références alors que ces deux opérations ne surviennent que très rarement la plupart du temps.
Pensons à la gestion de vues supplémentaires dans des modèles parfois très complexes et pourvus de nombreux objets, à la gestion des performances sur ces vues, à la gestion des indexes dans les tables de dimensions, à la possible association de notre entrepôt avec SSAS.
Bref, c’est une solution à garder dans un coin de la tête, mais très rarement profitable.