
Cette article fait partie de la série SQL Server en IAAS sur Azure vous pouvez retrouver tous les articles depuis => ici <=
1 – La configuration « Par Défaut »
La configuration par défaut, c’est celle que vous obtenez après un savant, suivant suivant suivant comme on l’aime avec les produits Microsoft, ce n’est potentiellement pas la manière la plus efficace mais elle à le mérite d’être simple à mettre en place.
Étape 1 : Bench I/O
Nous utiliserons CrystalDiskMark pour sa simplicité d’utilisation, vous pouvez retrouver les différents outils proposé par Brent Ozar ici.
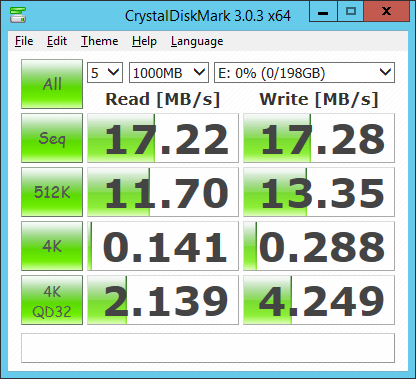
| Lecture | Ecriture | |
| Mb/s – 4K | 0,1 | 0,3 |
| IOPS | 36 | 74 |
| IOPS 32K | 2 | 5 |
Bon ça ne fait pas rêver, plus d’info sur la compréhension de ces chiffres sur cet excellent article http://www.brentozar.com/archive/2012/03/how-fast-your-san-or-how-slow/ et plus particulièrement ce passage :
-
Seq – long, sequential operations. For SQL Server, this is somewhat akin to doing backups or doing table scans of perfectly defragmented data, like a data warehouse.
-
512K – random large operations one at a time. This doesn’t really match up to how SQL Server works.
-
4K – random tiny operations one at a time. This is somewhat akin to a lightly loaded OLTP server.
-
4K QD32 – random tiny operations, but many done at a time. This is somewhat akin to an active OLTP server.
Étape 2 : La restauration de backup
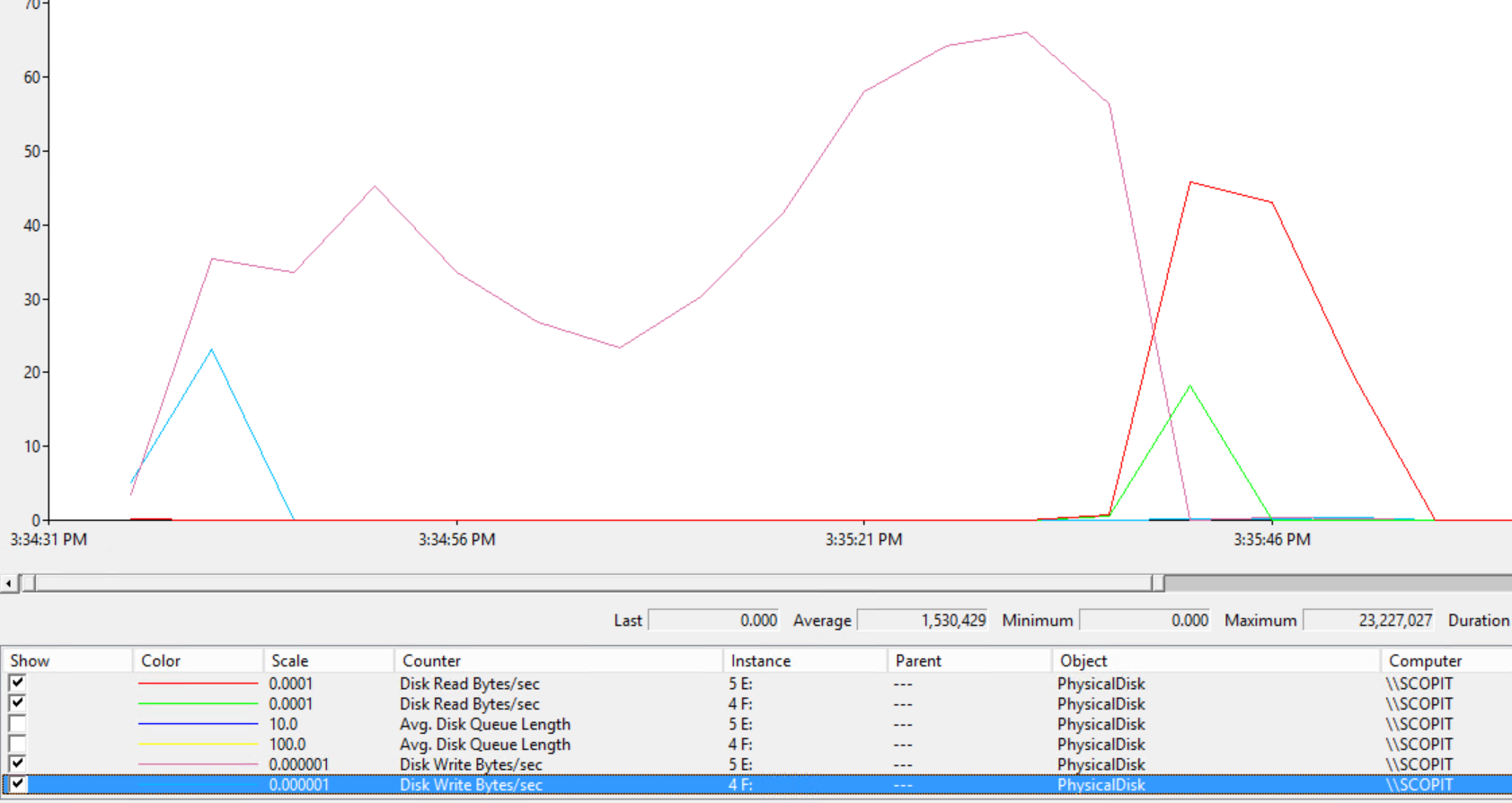
Contoso, un backup compressé de 645 Mo que l’on va restaurer depuis le disque temporaire vers nos deux disques (E: Data F: Log)
RESTORE DATABASE [Contoso] FROM DISK = N'D:\ContosoRetailDW.bak' WITH FILE = 1, MOVE N'ContosoRetailDW2.0' TO N'E:\Data\Contoso.mdf', MOVE N'ContosoRetailDW2.0_log' TO N'F:\Log\Contoso.ldf', NOUNLOAD, REPLACE, STATS = 5
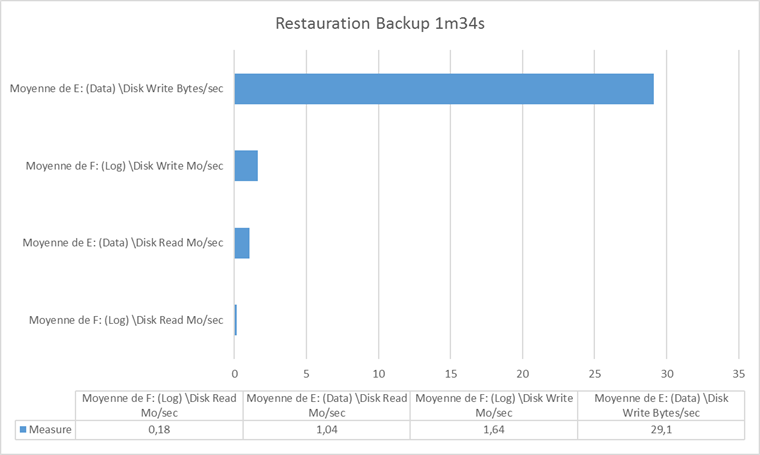
Il aura fallu dans cette configuration 1min34 (94 s) pour restaurer le backup soit une moyenne de 6,8 mo/s.
Vous voulez retrouver comment poser des traces, n’hésitez pas à consulter l’article de Christophe Laporte sur ce sujet !
Étape 3 : Charge OLTP avec HammerDB
Configuration :

Création de la base de test :

On remarque rapidement que le CPU et la mémoire ne sont vont pas être notre problème lors du remplissage de la base de test par HammerDb.
Le moment du test est arrivé, allons y doucement avec 5 utilisateurs et voyons combien notre instance SQL arrive à gérer de Transaction Par Minutes (TPM) et de NOPM (New Orders per minute)
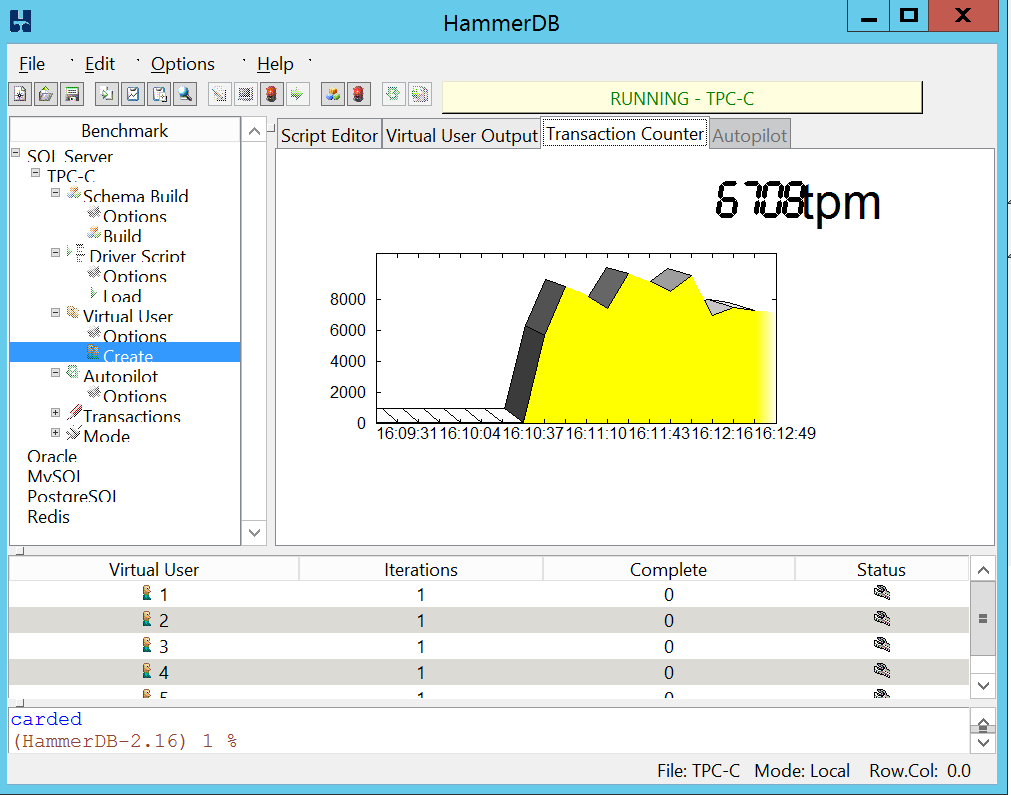
Résultat du test de 5 minutes
Vuser 1:Test complete, Taking end Transaction Count. Vuser 1:5 Virtual Users configured Vuser 1:TEST RESULT : System achieved 7846 SQL Server TPM at 1694 NOPM
Notre configuration à donc réussi à traiter 12492 transactions par minutes et 2728 nouvelles commandes par minutes.
Étape 4 : Test OLAP
Rien de tel qu’une grosse requête SQL qui joint toutes vos tables pour des besoins de reporting pour mettre à terre un serveur SQL, voyons comment notre configuration va réagir à la requête suivante :
SELECT DC.ChannelName ,DP.ProductName ,DPSC.ProductSubcategoryName ,DPC.ProductCategoryName ,DS.StoreName ,SUM([SalesQuantity]) AS [SalesQuantity] ,SUM([ReturnQuantity]) AS [ReturnQuantity] ,SUM([ReturnAmount]) AS [ReturnAmount] ,SUM([DiscountQuantity]) AS [DiscountQuantity] ,SUM([DiscountAmount]) AS [DiscountAmount] ,SUM([TotalCost]) AS [TotalCost] ,SUM([SalesAmount]) AS [SalesAmount] FROM [Contoso].[dbo].[FactSales] F INNER JOIN [Contoso].dbo.DimChannel DC ON F.channelKey = DC.ChannelKey INNER JOIN [Contoso].[dbo].[DimProduct] DP ON F.ProductKey = DP.ProductKey INNER JOIN [Contoso].[dbo].[DimProductSubcategory] DPSC ON DP.ProductSubcategoryKey = DPSC.ProductSubcategoryKey INNER JOIN [Contoso].[dbo].[DimProductCategory] DPC ON DPC.ProductCategoryKey = DPSC.ProductCategoryKey INNER JOIN [Contoso].[dbo].[DimStore] DS ON F.StoreKey = DS.StoreKey GROUP BY DC.ChannelName ,DP.ProductName ,DPSC.ProductSubcategoryName ,DPC.ProductCategoryName ,DS.StoreName
Verdict 1 minute 45 s sur cache froid.
Considérations sur cette configuration :
- Les performances sont très faible et l’I/O est clairement notre bottleneck dans chacun des tests.
- On est limité à 8 disques sur la machine que j’ai choisi, je vais donc vite atteindre des limites en nombre de bases de données si je veux garder 1 fichier (mdf/ldf) par disque pour avoir les meilleures performances.
- Afin d’obtenir plus de disque, je dois ajouter des CPU quand bien même je n’ai pas besoin de plus de puissance de calcul cela me reviendra donc plus chère.
- Durant les tests, les écarts entre chaque mesures peuvent être très important cela est certainement du à la mutualisation des ressources et à l’absence de garanti en nombre d’I/O minimum (Nous ne sommes pas en storage premium)
Une des approches pour améliorer les performances proposé dans le Performance Best Practices for SQL Server in Azure Virtual Machines est la mise en place de Windows Server Storage Pools, notre prochain test concernera donc une architecture à base de Pools.
Test de la configuration par défaut
Summary : Sûrement pas les meilleurs performances mais une facilité de mise en oeuvre importante.
One comment
[…] La configuration “Par Défaut” c’est à dire sur disque classique avec un fichier = une base => A retrouver ici […]