C’est avec un mélange de bonheur et de tristesse que je me prête au jeu des nouveautés Azure Data Factory de cette année.
Car si ces nouveautés sont plus que bienvenues tellement… elles sont évidentes et nécessaires. Elles ont tellement tardées à arriver que durant presque quatre années nous avons bricolé, alors que dans le même temps nous avons vu des dizaines de nouveautés sur les ADF Data Flows tout en étant toujours pas persuadé de vouloir utiliser les fonctionnalités ETL d’ADF tellement l’approche ELT est devenue le standard dans mes architectures.
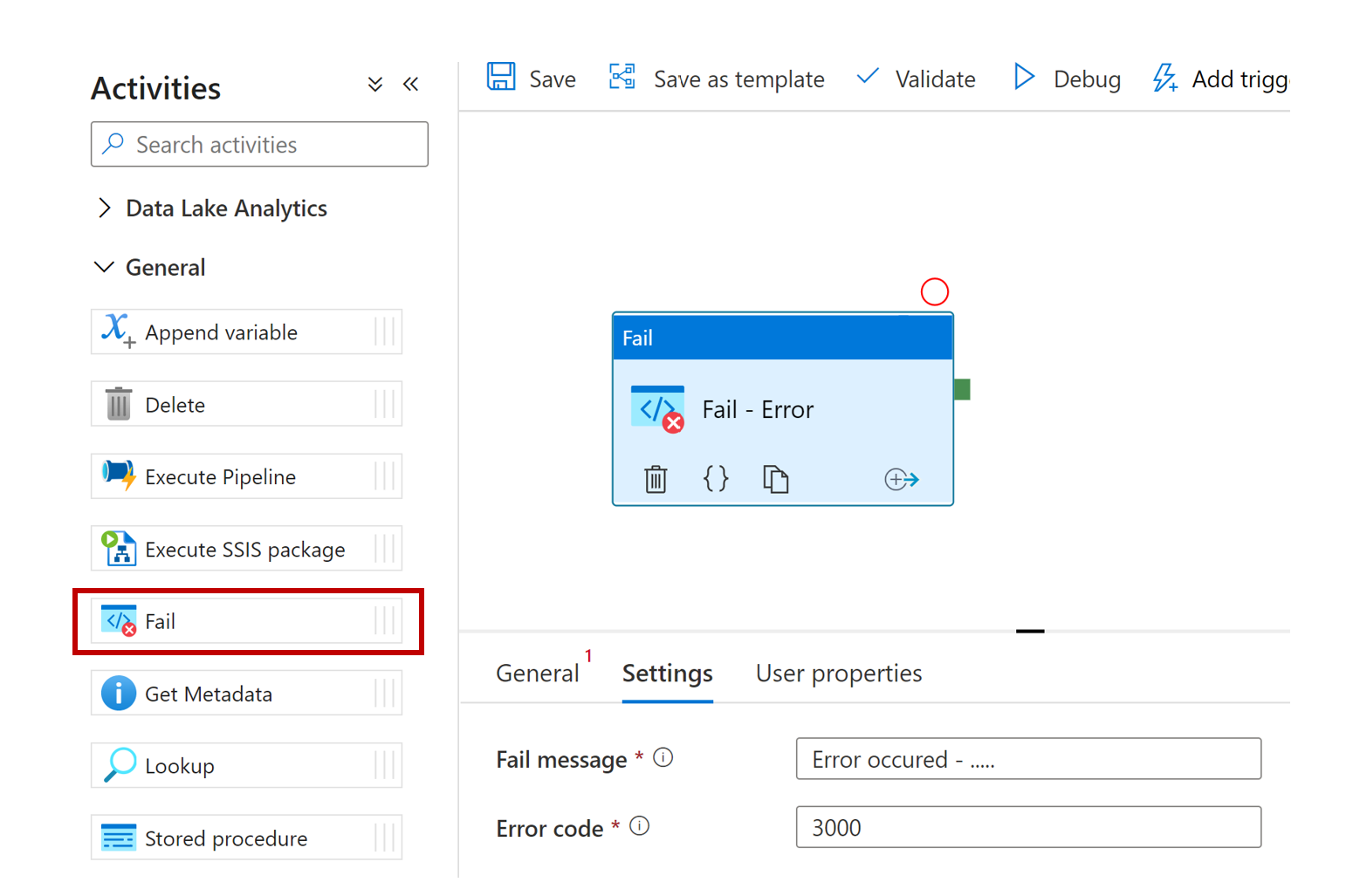
Activité Fail
Enfin ! Fini l’activité Web pour loguer un échec, ou la procédure stockée dédiée à générer un échec avec un message d’erreur. L’activité Fail est simple mais efficace.
{
"name": "Fail - Error",
"type": "Fail",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"message": "Error occured - .....",
"errorCode": "3000"
}
}L’activité permet donc de mettre le pipeline en erreur est d’obtenir message et code d’erreur dans les logs d’Azure Data Factory. Ainsi, si vous configurez les « diagnostics settings » :

Vous aurez accès aux logs niveau pipeline :
{
"Level": 4,
"correlationId": "9fae7d81-48d5-45d2-97b8-f79c40c56ee3",
"time": "2022-03-18T15:44:02.0973843Z",
"runId": "9fae7d81-48d5-45d2-97b8-f79c40c56ee3",
"resourceId": "/SUBSCRIPTIONS/C24EF419-76BF-4265-BB0D-E3E3F3086BE2/RESOURCEGROUPS/COMPLETE-BIG-DATA-ARCHITECTURE/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/ADF-COMPLETE",
"category": "SandboxPipelineRuns",
"level": "Error",
"operationName": "Demo Pipeline - Failed",
"pipelineName": "Demo Pipeline",
"start": "2022-03-18T15:44:00.4036687Z",
"end": "2022-03-18T15:44:02.0819109Z",
"status": "Failed",
"failureType": "UserError",
"location": "northeurope",
"properties": {
"Parameters": {},
"SystemParameters": {
"ExecutionStart": "2022-03-18T15:44:01.6652025Z",
"TriggerId": "f1086a76c1764fb58bdc784076204247",
"SubscriptionId": "c24ef419-76bf-4265-bb0d-e3e3f3086be2",
"PipelineRunRequestTime": "2022-03-18T15:44:00.4103101+00:00"
},
"Predecessors": [{
"Name": "Sandbox",
"Id": "f1086a76c1764fb58bdc784076204247",
"InvokedByType": "Manual"
}
],
"UserProperties": {},
"Annotations": [],
"Message": "Operation on target Fail - Error failed: Error occured - ....."
},
"tags": "{\"catalogUri\":\"https://gddp-catalog.purview.azure.com/catalog\"}",
"groupId": "9fae7d81-48d5-45d2-97b8-f79c40c56ee3"
}Ou au niveau activité :
{
"Level": 4,
"correlationId": "2f2c12d7-6d84-4e10-add9-05c426c17f64",
"time": "2022-03-18T15:45:27.7728764Z",
"activityRunId": "43eaa78d-f777-40d6-9090-2230ccd2fd25",
"pipelineRunId": "2f2c12d7-6d84-4e10-add9-05c426c17f64",
"resourceId": "/SUBSCRIPTIONS/C24EF419-76BF-4265-BB0D-E3E3F3086BE2/RESOURCEGROUPS/COMPLETE-BIG-DATA-ARCHITECTURE/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/ADF-COMPLETE",
"category": "SandboxActivityRuns",
"level": "Informational",
"operationName": "Fail - Error - InProgress",
"activityIterationCount": 1,
"pipelineName": "Demo Pipeline",
"activityName": "Fail - Error",
"start": "2022-03-18T15:45:27.6409618Z",
"end": "1601-01-01T00:00:00Z",
"status": "InProgress",
"location": "northeurope",
"properties": {
"Input": {
"message": "Error occured - .....",
"errorCode": "3000"
},
"Output": null,
"Error": {
"errorCode": "",
"message": "",
"failureType": "",
"target": "Fail - Error"
},
"UserProperties": {},
"Annotations": []
},
"activityType": "Fail",
"tags": "{\"catalogUri\":\"https://gddp-catalog.purview.azure.com/catalog\"}",
"recoveryStatus": "None",
"activityRetryCount": 0,
"billingResourceId": "/SUBSCRIPTIONS/C24EF419-76BF-4265-BB0D-E3E3F3086BE2/RESOURCEGROUPS/COMPLETE-BIG-DATA-ARCHITECTURE/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/ADF-COMPLETE"
}Avec ça, plus aucune raison de continuer de loguer dans votre logique métier (Stored Procedure, Base SQL) et toutes les raisons du monde d’utiliser les diagnostics settings pour votre monitoring !
Activité Script
Il devient enfin possible d’exécuter un script SQL depuis ADF officiellement (sans pirater une activité de Lookup 😉 ). Les services liés surpportés sont :
- Azure SQL Database
- Azure SQL Database Managed Instance
- Azure Synapse Analytics
- Oracle
- SQL Server
- Snowflake
La configuration est simple, on n’oublie pas de changer le Timeout par défaut de 7 jours à… quelque chose de plus réaliste.
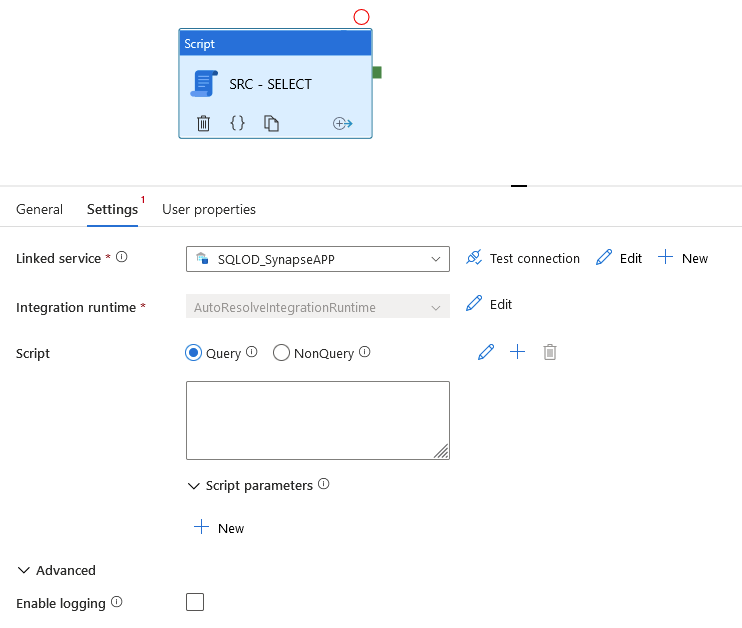
Plusieurs options sont intéressantes :
Query or NonQuery
Query permet de récupérer le résultat d’une requête sur l’output de l’activité. Il s’agit donc d’utiliser l’activité de Script exactement comme une activité de Lookup… Mais avec des options en plus telles que la gestion des paramètres…
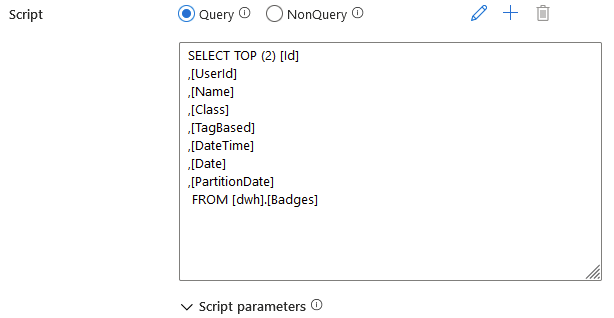
Retourne :
{
"resultSetCount": 1,
"recordsAffected": 0,
"resultSets": [
{
"rowCount": 2,
"rows": [
{
"Id": 34833754,
"UserId": 219,
"Name": "Mortarboard",
"Class": 3,
"TagBased": "False",
"DateTime": "2008-08-06T21:04:08.713Z",
"Date": "2008-08-06T00:00:00Z",
"PartitionDate": "2008-08-06T00:00:00Z"
},
{
"Id": 6465168,
"UserId": 1065,
"Name": "Mortarboard",
"Class": 3,
"TagBased": "False",
"DateTime": "2008-08-12T22:43:02.013Z",
"Date": "2008-08-12T00:00:00Z",
"PartitionDate": "2008-08-12T00:00:00Z"
}
]
}
],
"outputParameters": {},
"outputLogs": "",
"outputLogsLocation": "",
"outputTruncated": false,
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (North Europe)",
"executionDuration": 7,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "Hours"
}
]
}
}NonQuery permet d’exécuter une requête qui ne retournera pas de jeux de données tel qu’un truncate, un delete, une création de table… (DML / DDL)
Il est aussi possible d’activer les logs qui seront soit écrits dans un fichier sur un stockage Azure, soit dans la sortie de l’activité et qui correspond au message de retour associé à l’exécution de la requête.
"outputLogs": "Statement ID: {598AF5D8-9B15-4DF5-BE71-2F9948F1E13B} | Query hash: 0x390AF4BC69C7D7A1 | Distributed request ID: {AEA52726-5733-43F0-949B-3B4543A3F771}. Total size of data scanned is 1 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.\n",Copy – Upsert
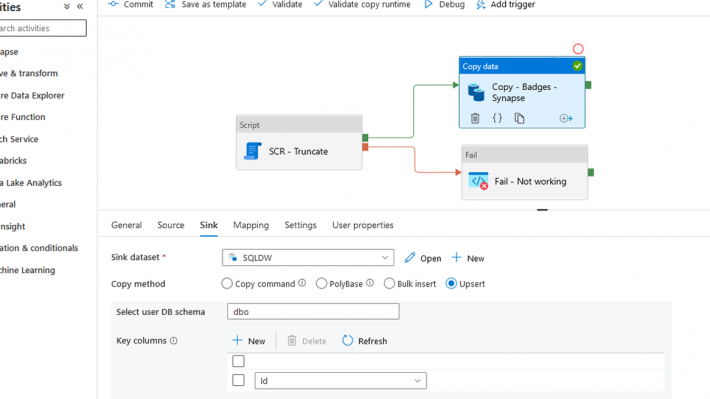
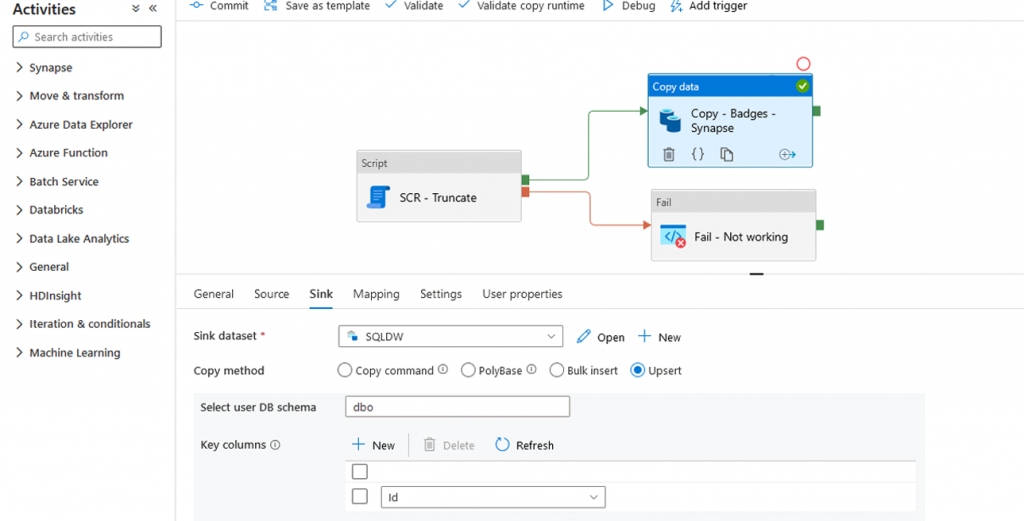
Il existe maintenant une nouvelle option dans l’activité de copie afin d’écrire la donnée en plus de Insert Stored Procedure, polybase*, copy command*, Bulk Insert* (*Lorsque le linked service est Synapse SQL Pool Dedicated) il s’agit de l’Upsert.

En sélectionnant l’option Upsert, il est nécessaire de renseigner la clé qui va permettre de vérifier si une ligne existe. Il s’agit ici de ma colonne Id. Il est possible d’écrire sur la TempDB de dataset qui va ensuite être comparé aux données de la table cible (et c’est d’ailleurs plutôt conseillé en cas de volume important).
Lors de l’exécution, deux nouvelles lignes apparaissent dans les logs qui correspondent à l’écriture des données dans la TempDB :
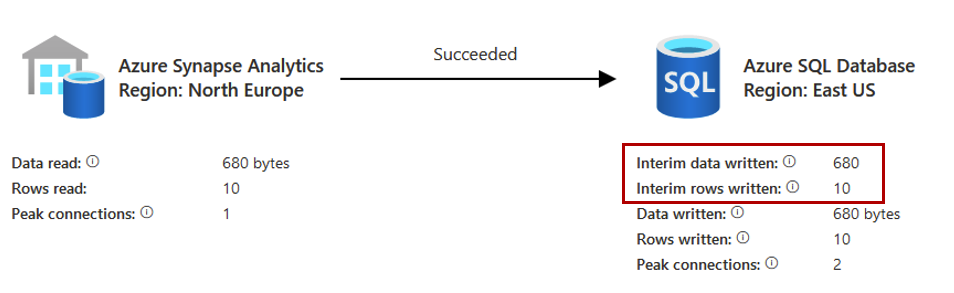
Mais que se passe t’il réellement sur le moteur SQL ?
1 – Le remplissage de la table temporaire
insert bulk [ ##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809] ([Id] Int, [UserId] Int, [Name] NVarChar(255) COLLATE Latin1_General_100_CI_AS, [Class] Int, [TagBased] NVarChar(10) COLLATE Latin1_General_100_CI_AS, [DateTime] DateTime, [Date] Date, [PartitionDate] DateTime) with (CHECK_CONSTRAINTS)2 – Désactiver la colonne identity si celle-ci existe
BEGIN TRY set IDENTITY_INSERT [dbo].[badges] on END TRY BEGIN CATCH END CATCH3 – Mettre à jour les enregistrements existants
update
[dbo].[badges]
set
[UserId] = [ ##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[UserId], [Name] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Name], [Class] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Class], [TagBased] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[TagBased], [DateTime] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[DateTime], [Date] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Date], [PartitionDate] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[PartitionDate] from [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809] where [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier >= @start and [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier < @end and [dbo].[badges].[Id] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Id]4 – Insérer les lignes non existantes
insert into [dbo].[badges] (
[Id], [UserId], [Name], [Class], [TagBased],
[DateTime], [Date], [PartitionDate]
)
select
[Id],
[UserId],
[Name],
[Class],
[TagBased],
[DateTime],
[Date],
[PartitionDate]
from
[ ##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809] where [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier >= @start and [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier < @end and not exists (select * from [dbo].[badges] where [dbo].[badges].[Id] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Id])5 – Ré-activer la colonne identity si elle existe
BEGIN TRY set IDENTITY_INSERT [dbo].[badges] on END TRY BEGIN CATCH END CATCHCette fonctionnalitée peut être intéressante pour minimiser la quantité de code nécessaire au scénario d’Upsert toutefois il faut garder en tête que :
- Il reste nécessaire d’insérer la totalité les lignes source dans la table
- Il reste nécessaire d’optimiser les performances de la clé de jointure (Index…) de la table de destination
- Les données sont intégrées en Bulk, cela est donc une mauvaise option sur Synapse SQL Pool Dedicated
Wish List
- Un peu d’amour pour l’activité de WebHook qui est un pilier de l’utilisation d’ADF (d’autant plus avec la limitation de 1 minute de l’activité Web). Le support des Secure Input / Ouput, l’ajout d’une notion de retry sont indispensables et pourtant absents.
- L’alignement d’ADF dans Synapse et hors Synapse (La build ne fonctionne que sur ADF)
- Une vraie notion de template / snippet facile à déployer et à mettre à jour. La solution actuelle est un cauchemar.
- J’en oublie sûrement, postez les en commentaire !
Mise à jour : Matthieu a souligné qu’un peu d’amour a été donné à l’activité Web https://techcommunity.microsoft.com/t5/azure-data-factory-blog/web-activity-response-timeout-improvement/ba-p/3260307 où la limite à 1 minute peut maintenant être configurée jusqu’à 10 minutes.

One comment
[…] Data Factory – News & Feelings avec 1539 vues en français et 1081 en […]