It is with a mixture of happiness and sadness that I will present some of the new ADF features.
Because if these innovations are more than welcome as they are obvious and necessary. They took so long to be released, that for almost four years we tinkered, while at the same time we saw dozens of new features on ADF Data Flows while still not being convinced that we wanted to use ADF’s ETL functionalities so much. As the ELT approach has become the standard in my architectures.
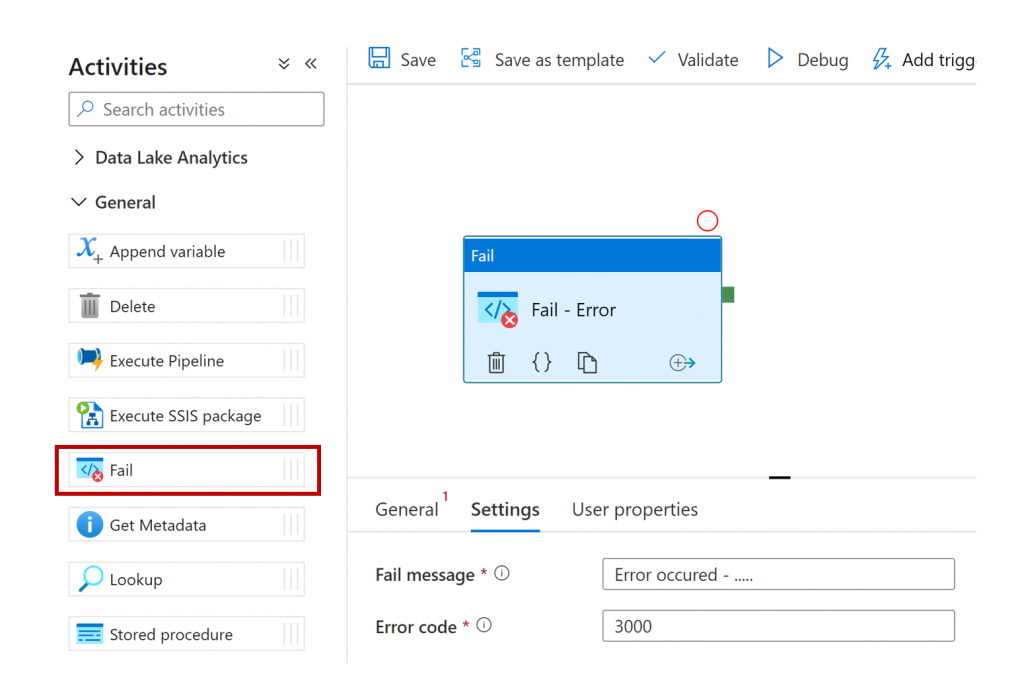
Fail activity
At last ! Gone is the web activity to log a failure, or a dedicated stored procedure to generate a failure with an error message. The Fail activity is simple but effective.
{
"name": "Fail - Error",
"type": "Fail",
"dependsOn": [],
"userProperties": [],
"typeProperties": {
"message": "Error occured - .....",
"errorCode": "3000"
}
}The Fail activity makes it possible to put the pipeline in error and to obtain an error message and code in the Azure Data Factory logs. So, if you configure the “diagnostics settings”:
You will have accès to logs at a pipeline level :
{
"Level": 4,
"correlationId": "9fae7d81-48d5-45d2-97b8-f79c40c56ee3",
"time": "2022-03-18T15:44:02.0973843Z",
"runId": "9fae7d81-48d5-45d2-97b8-f79c40c56ee3",
"resourceId": "/SUBSCRIPTIONS/C24EF419-76BF-4265-BB0D-E3E3F3086BE2/RESOURCEGROUPS/COMPLETE-BIG-DATA-ARCHITECTURE/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/ADF-COMPLETE",
"category": "SandboxPipelineRuns",
"level": "Error",
"operationName": "Demo Pipeline - Failed",
"pipelineName": "Demo Pipeline",
"start": "2022-03-18T15:44:00.4036687Z",
"end": "2022-03-18T15:44:02.0819109Z",
"status": "Failed",
"failureType": "UserError",
"location": "northeurope",
"properties": {
"Parameters": {},
"SystemParameters": {
"ExecutionStart": "2022-03-18T15:44:01.6652025Z",
"TriggerId": "f1086a76c1764fb58bdc784076204247",
"SubscriptionId": "c24ef419-76bf-4265-bb0d-e3e3f3086be2",
"PipelineRunRequestTime": "2022-03-18T15:44:00.4103101+00:00"
},
"Predecessors": [{
"Name": "Sandbox",
"Id": "f1086a76c1764fb58bdc784076204247",
"InvokedByType": "Manual"
}
],
"UserProperties": {},
"Annotations": [],
"Message": "Operation on target Fail - Error failed: Error occured - ....."
},
"tags": "{\"catalogUri\":\"https://gddp-catalog.purview.azure.com/catalog\"}",
"groupId": "9fae7d81-48d5-45d2-97b8-f79c40c56ee3"
}Or at an activity level :
{
"Level": 4,
"correlationId": "2f2c12d7-6d84-4e10-add9-05c426c17f64",
"time": "2022-03-18T15:45:27.7728764Z",
"activityRunId": "43eaa78d-f777-40d6-9090-2230ccd2fd25",
"pipelineRunId": "2f2c12d7-6d84-4e10-add9-05c426c17f64",
"resourceId": "/SUBSCRIPTIONS/C24EF419-76BF-4265-BB0D-E3E3F3086BE2/RESOURCEGROUPS/COMPLETE-BIG-DATA-ARCHITECTURE/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/ADF-COMPLETE",
"category": "SandboxActivityRuns",
"level": "Informational",
"operationName": "Fail - Error - InProgress",
"activityIterationCount": 1,
"pipelineName": "Demo Pipeline",
"activityName": "Fail - Error",
"start": "2022-03-18T15:45:27.6409618Z",
"end": "1601-01-01T00:00:00Z",
"status": "InProgress",
"location": "northeurope",
"properties": {
"Input": {
"message": "Error occured - .....",
"errorCode": "3000"
},
"Output": null,
"Error": {
"errorCode": "",
"message": "",
"failureType": "",
"target": "Fail - Error"
},
"UserProperties": {},
"Annotations": []
},
"activityType": "Fail",
"tags": "{\"catalogUri\":\"https://gddp-catalog.purview.azure.com/catalog\"}",
"recoveryStatus": "None",
"activityRetryCount": 0,
"billingResourceId": "/SUBSCRIPTIONS/C24EF419-76BF-4265-BB0D-E3E3F3086BE2/RESOURCEGROUPS/COMPLETE-BIG-DATA-ARCHITECTURE/PROVIDERS/MICROSOFT.DATAFACTORY/FACTORIES/ADF-COMPLETE"
}With that, there is no longer any reason to continue logging into your business logic (Stored Procedure, SQL Base) and all the reasons in the world to use the diagnostics settings for your monitoring!
Script activity
It finally becomes possible to execute an SQL script from ADF officially (without hacking a Lookup activity 😉 ). Supported linked services are:
- Azure SQL Database
- Azure SQL Database Managed Instance
- Azure Synapse Analytics
- Oracle
- SQL Server
- Snowflake
The configuration is simple, we don’t forget to change the default Timeout from 7 days to… something more realistic.
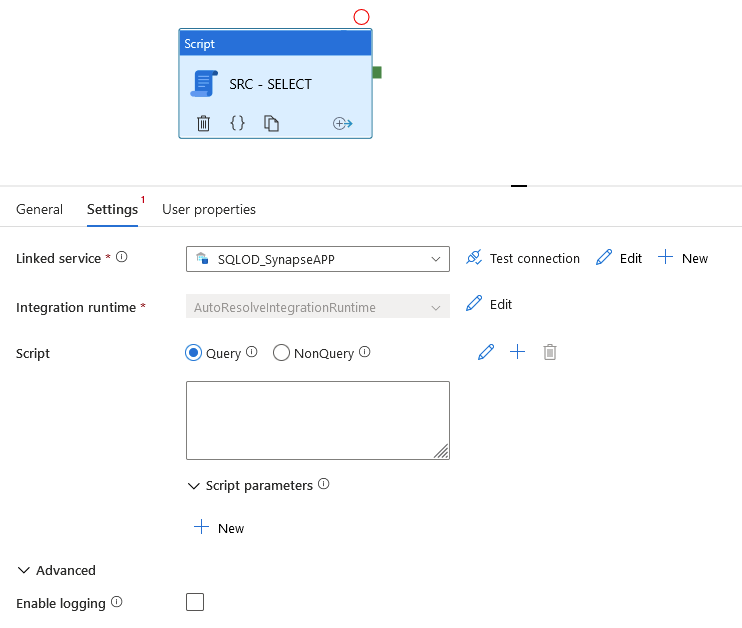
Multiple options are interesting :
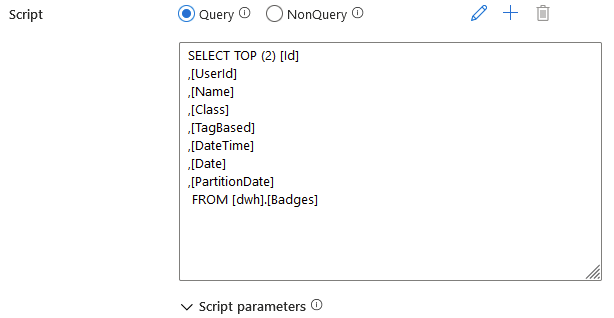
Query or NonQuery
Query is used to retrieve the result of a query on the output of the activity. It is therefore a question of using the Script activity exactly like a Lookup activity… But with additional options such as parameter management…
Return :
{
"resultSetCount": 1,
"recordsAffected": 0,
"resultSets": [
{
"rowCount": 2,
"rows": [
{
"Id": 34833754,
"UserId": 219,
"Name": "Mortarboard",
"Class": 3,
"TagBased": "False",
"DateTime": "2008-08-06T21:04:08.713Z",
"Date": "2008-08-06T00:00:00Z",
"PartitionDate": "2008-08-06T00:00:00Z"
},
{
"Id": 6465168,
"UserId": 1065,
"Name": "Mortarboard",
"Class": 3,
"TagBased": "False",
"DateTime": "2008-08-12T22:43:02.013Z",
"Date": "2008-08-12T00:00:00Z",
"PartitionDate": "2008-08-12T00:00:00Z"
}
]
}
],
"outputParameters": {},
"outputLogs": "",
"outputLogsLocation": "",
"outputTruncated": false,
"effectiveIntegrationRuntime": "AutoResolveIntegrationRuntime (North Europe)",
"executionDuration": 7,
"durationInQueue": {
"integrationRuntimeQueue": 0
},
"billingReference": {
"activityType": "PipelineActivity",
"billableDuration": [
{
"meterType": "AzureIR",
"duration": 0.016666666666666666,
"unit": "Hours"
}
]
}
}NonQuery allows you to execute a query that will not return data sets such as a truncate, a delete, a table creation… (DML / DDL)
It is also possible to activate the logs which will either be written to a file on an Azure storage, or in the output of the activity and which corresponds to the return message associated with the execution of the request.
"outputLogs": "Statement ID: {598AF5D8-9B15-4DF5-BE71-2F9948F1E13B} | Query hash: 0x390AF4BC69C7D7A1 | Distributed request ID: {AEA52726-5733-43F0-949B-3B4543A3F771}. Total size of data scanned is 1 megabytes, total size of data moved is 1 megabytes, total size of data written is 0 megabytes.\n",Copy – Upsert
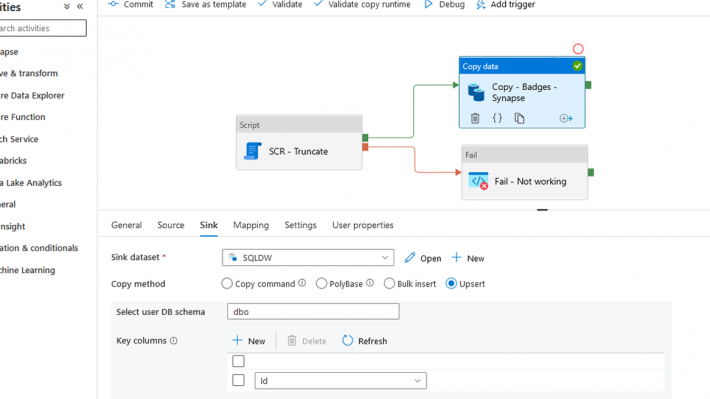
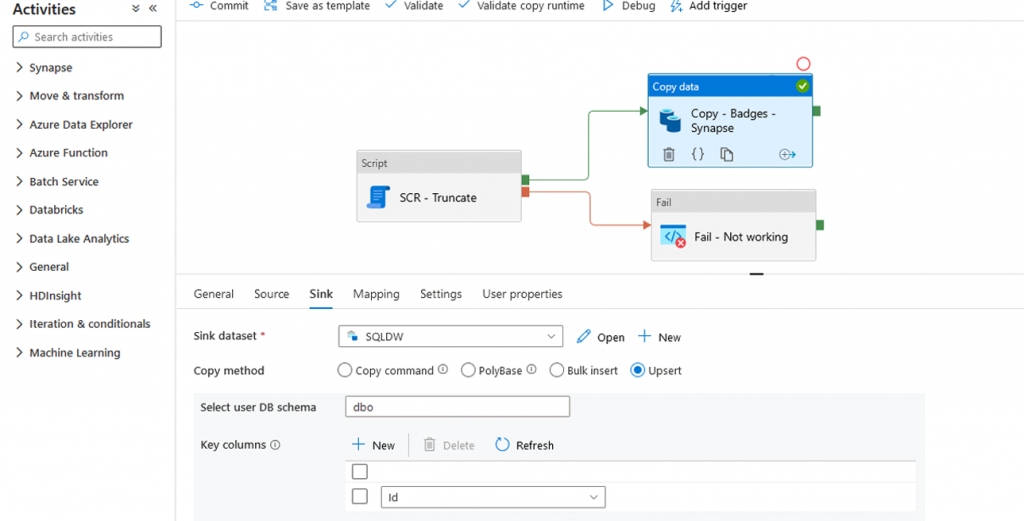
There is now a new option in the copy activity to write the data in addition to Insert, Stored Procedure, polybase*, copy command*, Bulk Insert* (*When the linked service is Synapse SQL Pool Dedicated), the Upsert.

By selecting the Upsert option, it is necessary to enter the key that will allow to check if a row exists. This is my Id column. It is possible to write to the dataset TempDB which will then be compared to the data of the target table (and this is also rather recommended in the event of a large volume).
During execution, two new lines appear in the logs which correspond to the writing of data to the TempDB:
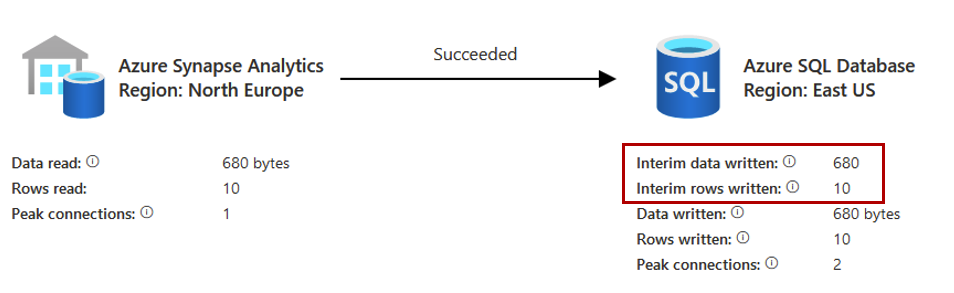
But what is really happening on the SQL engine?
1 – Filling the temporary table
insert bulk [ ##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809] ([Id] Int, [UserId] Int, [Name] NVarChar(255) COLLATE Latin1_General_100_CI_AS, [Class] Int, [TagBased] NVarChar(10) COLLATE Latin1_General_100_CI_AS, [DateTime] DateTime, [Date] Date, [PartitionDate] DateTime) with (CHECK_CONSTRAINTS)2 – Disable the identity column if it exists
BEGIN TRY set IDENTITY_INSERT [dbo].[badges] on END TRY BEGIN CATCH END CATCH3 – Update existing records
update
[dbo].[badges]
set
[UserId] = [ ##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[UserId], [Name] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Name], [Class] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Class], [TagBased] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[TagBased], [DateTime] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[DateTime], [Date] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Date], [PartitionDate] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[PartitionDate] from [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809] where [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier >= @start and [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier < @end and [dbo].[badges].[Id] = [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].[Id]4 – Insert non-existing rows
insert into [dbo].[badges] (
[Id], [UserId], [Name], [Class], [TagBased],
[DateTime], [Date], [PartitionDate]
)
select
[Id],
[UserId],
[Name],
[Class],
[TagBased],
[DateTime],
[Date],
[PartitionDate]
from
[ ##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809] where [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier >= @start and [##InterimTable_a9551848-47d3-47a6-a057-ab5a835c3809].BatchIdentifier < @end and not exists (select * from [dbo].[badges] where [dbo].[badges].[Id] = [##InterimTable_a9551848-47d3-47a6-a057-a5 – Re-enable the identity column if it exists
TRY set IDENTITY_INSERT [dbo].[badges] on END TRY BEGIN CATCH END CATCHThis feature can be interesting to minimize the amount of code needed for the Upsert scenario, however keep in mind that:
- It remains necessary to insert all the source rows in the table
- It is still necessary to optimize the performance of the join key (Index…) of the destination table
- Data is integrated in Bulk, so this is a bad option on Synapse SQL Pool Dedicated
Wish List
- Some love for WebHook activity which is a key stone of using ADF (more so with the 1 minute limitation of web activity). The support of Secure Input / Ouput, the addition of a notion of retry are essential and yet absent.
- ADF alignment in Synapse and out of Synapse (Build only works on ADF)
- A real concept of template / snippet easy to deploy and update. The current solution is a nightmare.
- I probably forgot some, post them in the comments!
Update : Matthieu highlighted some love given to the Web Activity https://techcommunity.microsoft.com/t5/azure-data-factory-blog/web-activity-response-timeout-improvement/ba-p/3260307 where the 1 minute limite can now be configure up to 10 minutes.

One comment
[…] Azure Data Factory – News & Feelings avec 1539 vues en français et 1081 en anglais […]